DerivaML
DerivaML is a Python library for reproducible machine learning workflows backed by a Deriva catalog. It captures code provenance, input data versions, configuration, and outputs so experiments can be reproduced, cited, and shared.
!!! info "Upgrading from a previous release?" If you are upgrading an existing project, see Migrating from previous versions for the list of breaking changes and how to update your code.
What deriva-ml does
Four core concepts organize the library:
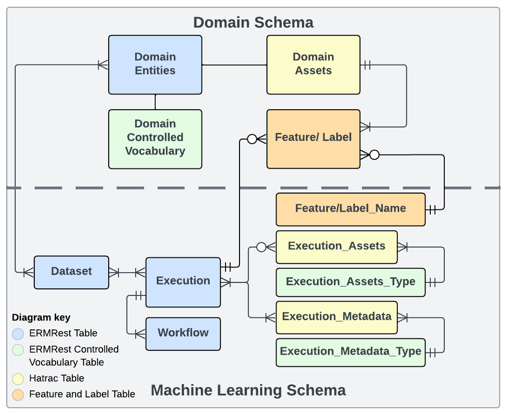
- Catalog — the schema + data store. An ERMrest-backed Deriva catalog with domain tables (Subject, Image, Observation, etc.) and an ML schema (Dataset, Execution, Workflow, Feature_Name).
- Dataset — a versioned, named collection of RIDs. Backs onto catalog snapshots so a named version always resolves the same rows.
- Execution — a tracked run of a Workflow. Captures inputs, outputs, environment, and status with full provenance.
- Feature — structured, provenance-linked annotations on existing rows. The unit of record for labels, predictions, and derived metadata.
When to use deriva-ml
Strong fit:
- Research labs where data governance, audit trails, and multi-annotator ground truth are first-class requirements.
- Multi-site collaborations that need citable dataset identifiers and reproducible execution records.
- Biomedical imaging, clinical records, or similar domains with structured schemas and vocabulary-controlled annotations.
Weaker fit:
- Quick single-dataset experiments where a folder of files and git is enough. deriva-ml has a non-trivial setup cost; don't pay it without the governance need.
- Online feature-serving for low-latency inference. deriva-ml is research-oriented; Feast / Tecton are better for that.
See also: Deriva-ML: A Continuous FAIRness Approach to Reproducible Machine Learning Models (Li et al., 2024, IEEE e-Science).
Experiments
DerivaML organizes ML activities into experiments. An experiment is a GitHub repository that holds the executable and human-readable sides of a research project; the catalog stores the what (data, RIDs, lineage), the experiment repository stores the how and the why:
- Code — model implementations, data-loading scripts, notebooks.
- Configuration — hydra-zen configs (Python, not YAML) declaring which catalog, which datasets, which workflow, which hyperparameters.
- Tacit knowledge —
tacit-knowledge.mdat the repo root, capturing the why behind decisions, dead ends explored, and the project's conventions. - Provenance link — every execution from this repo records the git
commit hash on the
Workflowrow, so a result can be traced to the exact code that produced it.
Starting a new experiment
Bootstrap a new experiment from the deriva-ml-model-template repository. It provides:
- Hydra-zen configuration scaffolding
- CLI entry points (
deriva-ml-run,deriva-ml-run-notebook) - GitHub Actions for versioning and documentation deployment
- An example model (CIFAR-10) with config variants you can replace with your own
- A
tacit-knowledge.mdskeleton ready for your project's first entry
These docs cover the deriva-ml library itself, for developers who already have an experiment repository and want to understand the library's concepts and APIs. Start with the User Guide for a task-oriented walkthrough, or jump to the API Reference for per-method documentation.
Further reading
The underlying FAIR-data principles are described in:
Dempsey, William, Ian Foster, Scott Fraser, and Carl Kesselman. "Sharing begins at home: how continuous and ubiquitous FAIRness can enhance research productivity and data reuse." Harvard Data Science Review 4, no. 3 (2022). PDF
The deriva-ml architecture and design decisions are described in:
Li, Zhiwei, Carl Kesselman, Mike D'Arcy, Michael Pazzani, and Benjamin Yizing Xu. "Deriva-ML: A Continuous FAIRness Approach to Reproducible Machine Learning Models." In 2024 IEEE 20th International Conference on e-Science (e-Science), pp. 1-10. IEEE, 2024. PDF