DerivaML Class
The DerivaML class provides a range of methods to interact with a Deriva catalog.
These methods assume tha tthe catalog contains a deriva-ml and a domain schema.
Data Catalog: The catalog must include both the domain schema and a standard ML schema for effective data management.
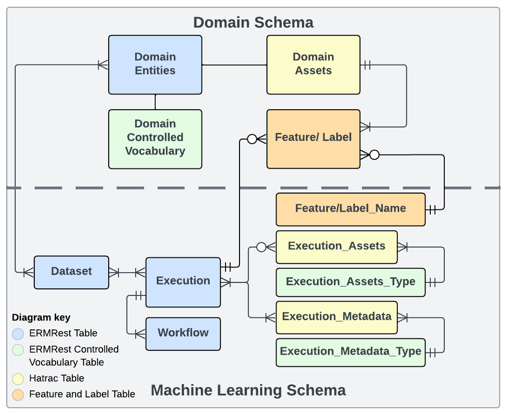
- Domain schema: The domain schema includes the data collected or generated by domain-specific experiments or systems.
- ML schema: Each entity in the ML schema is designed to capture details of the ML development process. It including the following tables
- A Dataset represents a data collection, such as aggregation identified for training, validation, and testing purposes.
- A Workflow represents a specific sequence of computational steps or human interactions.
- An Execution is an instance of a workflow that a user instantiates at a specific time.
- An Execution Asset is an output file that results from the execution of a workflow.
- An Execution Metadata is an asset entity for saving metadata files referencing a given execution.
Core module for DerivaML.
This module provides the primary public interface to DerivaML functionality. It exports the main DerivaML class along with configuration, definitions, and exceptions needed for interacting with Deriva-based ML catalogs.
Key exports
- DerivaML: Main class for catalog operations and ML workflow management.
- DerivaMLConfig: Configuration class for DerivaML instances.
- Exceptions: DerivaMLException and specialized exception types.
- Definitions: Type definitions, enums, and constants used throughout the package.
Example
from deriva_ml.core import DerivaML, DerivaMLConfig # doctest: +SKIP ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP datasets = ml.find_datasets() # doctest: +SKIP
BuiltinTypes
module-attribute
BuiltinTypes = BuiltinType
Alias for BuiltinType from deriva-py's deriva.core.typed.
Both BuiltinType and BuiltinTypes are part of deriva-ml's
public API; they resolve to the same class.
ColumnDefinition
module-attribute
ColumnDefinition = ColumnDef
Alias for ColumnDef from deriva-py's deriva.core.typed.
Both ColumnDef and ColumnDefinition are part of deriva-ml's
public API; they resolve to the same class.
TableDefinition
module-attribute
TableDefinition = TableDef
Alias for TableDef from deriva-py's deriva.core.typed.
Both TableDef and TableDefinition are part of deriva-ml's
public API; they resolve to the same class.
DerivaML
Bases: PathBuilderMixin, RidResolutionMixin, VocabularyMixin, WorkflowMixin, FeatureMixin, DatasetMixin, AssetMixin, ExecutionMixin, FileMixin, AnnotationMixin, DerivaMLCatalog
Core class for machine learning operations on a Deriva catalog.
This class provides core functionality for managing ML workflows, features, and datasets in a Deriva catalog. It handles data versioning, feature management, vocabulary control, and execution tracking.
Method naming convention
find_*methods search the catalog for entities of a kind, optionally filtered. Examples:find_features(table=None),find_datasets(),find_workflows(),find_executions(),find_experiments(),find_assets().find_*returns everything that matches; pass arguments to narrow the search.list_*methods enumerate things scoped to a specific entity passed as the first argument. Examples:list_assets(asset_table),list_dataset_members(dataset),list_dataset_children(dataset),list_workflow_executions(workflow),list_vocabulary_terms(table).list_*always has a "scope" argument; there is no scope-lesslist_*flavor for entities of a given kind — usefind_*for that.
So: "all features on the catalog" → find_features(); "all features on table T" →
find_features(T) (scoping is a filter); "all members of dataset D" →
list_dataset_members(D) (scoping is the parent entity itself). There is no
list_features() because features aren't scoped to a parent entity in the way
dataset members are scoped to a dataset.
Attributes:
| Name | Type | Description |
|---|---|---|
host_name |
str
|
Hostname of the Deriva server (e.g., 'deriva.example.org'). |
catalog_id |
Union[str, int]
|
Catalog identifier or name. |
domain_schemas |
frozenset[str]
|
Schema names for domain-specific tables and relationships. |
model |
DerivaModel
|
ERMRest model for the catalog. |
working_dir |
Path
|
Directory for storing computation data and results. |
cache_dir |
Path
|
Directory for caching downloaded datasets. |
ml_schema |
str
|
Schema name for ML-specific tables (default: 'deriva_ml'). |
configuration |
ExecutionConfiguration
|
Current execution configuration. |
project_name |
str
|
Name of the current project. |
start_time |
datetime
|
Timestamp when this instance was created. |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP ml.create_feature('my_table', 'new_feature') # doctest: +SKIP ml.add_term('vocabulary_table', 'new_term', description='Description of term') # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 1236 1237 1238 1239 1240 1241 1242 1243 1244 1245 1246 1247 1248 1249 1250 1251 1252 1253 1254 1255 1256 1257 1258 1259 1260 1261 1262 1263 1264 1265 1266 1267 1268 1269 1270 1271 1272 1273 1274 1275 1276 1277 1278 1279 1280 1281 1282 1283 1284 1285 1286 1287 1288 1289 1290 1291 1292 1293 1294 1295 1296 1297 1298 1299 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1312 1313 1314 1315 1316 1317 1318 1319 1320 1321 1322 1323 1324 1325 1326 1327 1328 1329 1330 1331 1332 1333 1334 1335 1336 1337 1338 1339 1340 1341 1342 1343 1344 1345 1346 1347 1348 1349 1350 1351 1352 1353 1354 1355 1356 1357 1358 1359 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380 1381 1382 1383 1384 1385 1386 1387 1388 1389 1390 1391 1392 1393 1394 1395 1396 1397 1398 1399 1400 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1416 1417 1418 1419 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469 1470 1471 1472 1473 1474 1475 1476 1477 1478 1479 1480 1481 1482 1483 1484 1485 1486 1487 1488 1489 1490 1491 1492 1493 1494 1495 1496 1497 1498 1499 1500 1501 1502 1503 1504 1505 1506 1507 1508 1509 1510 1511 1512 1513 1514 1515 1516 1517 1518 1519 1520 1521 1522 1523 1524 1525 1526 1527 1528 1529 1530 1531 1532 1533 1534 1535 1536 1537 1538 1539 1540 1541 1542 1543 1544 1545 1546 1547 1548 1549 1550 1551 1552 1553 1554 1555 1556 1557 1558 1559 1560 1561 1562 1563 1564 1565 1566 1567 1568 1569 1570 1571 1572 1573 1574 1575 1576 1577 1578 1579 1580 1581 1582 1583 1584 1585 1586 1587 1588 1589 1590 1591 1592 1593 1594 1595 1596 1597 1598 1599 1600 1601 1602 1603 1604 1605 1606 1607 1608 1609 1610 1611 1612 1613 1614 1615 1616 1617 1618 1619 1620 1621 1622 1623 1624 1625 1626 1627 1628 1629 1630 1631 1632 1633 1634 1635 1636 1637 1638 1639 1640 1641 1642 1643 1644 1645 1646 1647 1648 1649 1650 1651 1652 1653 1654 1655 1656 1657 1658 1659 1660 1661 1662 1663 1664 1665 1666 1667 1668 1669 1670 1671 1672 1673 1674 1675 1676 1677 1678 1679 1680 1681 1682 1683 1684 1685 1686 1687 1688 1689 1690 1691 1692 1693 1694 1695 1696 1697 1698 1699 1700 1701 1702 1703 1704 1705 1706 1707 1708 1709 1710 1711 1712 1713 1714 1715 1716 1717 1718 1719 1720 1721 1722 1723 1724 1725 1726 1727 1728 1729 1730 1731 1732 1733 1734 1735 1736 1737 1738 1739 1740 1741 1742 1743 1744 1745 1746 1747 1748 1749 1750 1751 1752 1753 1754 1755 1756 1757 1758 1759 1760 1761 1762 1763 1764 1765 1766 1767 1768 1769 1770 1771 1772 1773 1774 1775 1776 1777 1778 1779 1780 1781 1782 1783 1784 1785 1786 1787 1788 1789 1790 1791 1792 1793 1794 1795 1796 1797 1798 1799 1800 1801 1802 1803 1804 1805 1806 1807 1808 1809 1810 1811 1812 1813 1814 1815 1816 1817 1818 1819 1820 1821 1822 1823 1824 1825 1826 1827 1828 1829 1830 1831 1832 1833 1834 1835 1836 1837 1838 1839 1840 1841 1842 1843 1844 1845 1846 1847 1848 1849 1850 1851 1852 1853 1854 1855 1856 1857 1858 1859 1860 1861 1862 1863 1864 1865 1866 1867 1868 1869 1870 1871 1872 1873 1874 1875 1876 1877 1878 1879 1880 1881 1882 1883 1884 1885 1886 1887 1888 1889 1890 1891 1892 1893 1894 1895 1896 1897 1898 1899 1900 1901 1902 1903 1904 1905 1906 1907 1908 1909 1910 1911 1912 1913 1914 1915 1916 1917 1918 1919 1920 1921 1922 1923 1924 1925 1926 1927 1928 1929 1930 1931 1932 1933 1934 1935 1936 1937 1938 1939 1940 1941 1942 1943 1944 1945 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022 2023 2024 2025 2026 2027 2028 | |
catalog_provenance
property
catalog_provenance: (
"CatalogProvenance | None"
)
Get the provenance information for this catalog.
Returns provenance information if the catalog has it set. This includes information about how the catalog was created (clone, create, schema), who created it, when, and any workflow information.
For cloned catalogs, additional details about the clone operation are
available in the clone_details attribute.
Returns:
| Type | Description |
|---|---|
'CatalogProvenance | None'
|
CatalogProvenance if available, None otherwise. |
Example
ml = DerivaML('localhost', '45') # doctest: +SKIP prov = ml.catalog_provenance # doctest: +SKIP if prov: # doctest: +SKIP ... print(f"Created: {prov.created_at} by {prov.created_by}") ... print(f"Method: {prov.creation_method}") ... if prov.is_clone: ... print(f"Cloned from: {prov.clone_details.source_hostname}")
mode
property
mode: ConnectionMode
Current connection mode.
Returns:
| Type | Description |
|---|---|
ConnectionMode
|
The ConnectionMode this DerivaML instance was constructed |
ConnectionMode
|
with. Drives whether writes go live to the catalog (online) |
ConnectionMode
|
or stage in SQLite for later upload (offline). See spec §2.1. |
Example
ml.mode is ConnectionMode.online # doctest: +SKIP True
workspace
property
workspace: 'Workspace'
Per-catalog Workspace for local caching, denormalization, and asset manifests.
Backed by Workspace under {working_dir}/catalogs/{host}__{cat}/
working.db. Shared across invocations of scripts that use the same
working directory.
Example::
# Cache a full table
df = ml.cache_table("Subject")
# Check what's cached
ml.workspace.list_cached_results()
__del__
__del__() -> None
Cleanup method to handle incomplete executions.
Best-effort abort on DerivaML shutdown — only for executions that
died mid-flight (i.e., still in Created or Running). Any
post-Running status (Stopped, Failed, Pending_Upload,
Uploaded, Aborted) is treated as terminal here: the user
has either committed cleanly via the context manager or
explicitly transitioned the execution, and a forced abort would
either be a no-op or a wrongful state change.
Forcing a transition during __del__ is also unsafe at object-
teardown time: Python's GC ordering means the underlying
ErmrestCatalog HTTP session may already be finalized, in
which case the catalog PUT would crash with 'NoneType' object
has no attribute 'get' (the catalog's _session reads as
None). Limiting the abort to non-terminal states avoids the
common case where __exit__ already moved the execution to
Stopped and __del__ would otherwise re-transition to
Aborted against a dead session.
Source code in src/deriva_ml/core/base.py
399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 | |
__init__
__init__(
hostname: str,
catalog_id: str | int,
domain_schemas: str
| set[str]
| None = None,
default_schema: str | None = None,
project_name: str | None = None,
cache_dir: str | Path | None = None,
working_dir: str
| Path
| None = None,
hydra_runtime_output_dir: str
| Path
| None = None,
ml_schema: str = ML_SCHEMA,
logging_level: int = logging.WARNING,
deriva_logging_level: int = logging.WARNING,
credential: dict | None = None,
s3_bucket: str | None = None,
use_minid: bool | None = None,
clean_execution_dir: bool = True,
mode: ConnectionMode
| str = ConnectionMode.online,
reuse_schema_json: dict
| None = None,
) -> None
Initializes a DerivaML instance.
This method will connect to a catalog and initialize local configuration for the ML execution. This class is intended to be used as a base class on which domain-specific interfaces are built.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
hostname
|
str
|
Hostname of the Deriva server. |
required |
catalog_id
|
str | int
|
Catalog ID. Either an identifier or a catalog name. |
required |
domain_schemas
|
str | set[str] | None
|
Optional set of domain schema names. If None, auto-detects all non-system schemas. Use this when working with catalogs that have multiple user-defined schemas. |
None
|
default_schema
|
str | None
|
The default schema for table creation operations. If None and there is exactly one domain schema, that schema is used. If there are multiple domain schemas, this must be specified for table creation to work without explicit schema parameters. |
None
|
ml_schema
|
str
|
Schema name for ML schema. Used if you have a non-standard configuration of deriva-ml. |
ML_SCHEMA
|
project_name
|
str | None
|
Project name. Defaults to name of default_schema. |
None
|
cache_dir
|
str | Path | None
|
Directory path for caching data downloaded from the Deriva server as bdbag. If not provided, will default to working_dir. |
None
|
working_dir
|
str | Path | None
|
Directory path for storing data used by or generated by any computations. If no value is provided, will default to ${HOME}/deriva_ml |
None
|
s3_bucket
|
str | None
|
S3 bucket URL for dataset bag storage (e.g., 's3://my-bucket'). If provided, enables MINID creation and S3 upload for dataset exports. If None, MINID functionality is disabled regardless of use_minid setting. |
None
|
use_minid
|
bool | None
|
Use the MINID service when downloading dataset bags. Only effective when s3_bucket is configured. If None (default), automatically set to True when s3_bucket is provided, False otherwise. |
None
|
clean_execution_dir
|
bool
|
Whether to automatically clean up execution working directories after successful upload. Defaults to True. Set to False to retain local copies. |
True
|
mode
|
ConnectionMode | str
|
Connection mode for this instance. |
online
|
reuse_schema_json
|
dict | None
|
Internal. A pre-parsed ermrest |
None
|
Source code in src/deriva_ml/core/base.py
246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 | |
add_dataset_element_type
add_dataset_element_type(
element: str | Table,
) -> Table
Make it possible to add objects from element table to a dataset.
Creates a new association table linking Dataset to the given table, then updates catalog annotations so the new type is included in bag-export specs. If the workspace ORM was already built, it is rebuilt to pick up the new association table — the ORM is eagerly constructed at init time and does not see DDL changes applied after that point.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
element
|
str | Table
|
Name of the table (str) or Table object to register as a valid dataset element type. |
required |
Returns:
| Type | Description |
|---|---|
Table
|
The Table object that was registered. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If |
DerivaMLTableTypeError
|
If the table is a system or ML table and cannot be a dataset element type. |
Example
ml.add_dataset_element_type("Image") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/dataset.py
352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 | |
add_features
add_features(*args, **kwargs) -> int
Retired — use exe.add_features(records) inside an execution context.
DerivaML.add_features has been removed. Feature writes must go
through the execution context so that provenance is tracked and values
are staged for atomic upload.
Replacement::
with ml.create_execution(config).execute() as exe:
exe.add_features(records)
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
Always. Points at the replacement API. |
Source code in src/deriva_ml/core/mixins/feature.py
428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 | |
add_files
add_files(
files: Iterable[FileSpec],
execution_rid: RID,
dataset_types: str
| list[str]
| None = None,
description: str = "",
chunk_size: int = 500,
*,
root_name: str | None = None,
) -> "Dataset"
Register external file references and record the source dataset as the execution's input.
Inserts a File-table row per file (URL + MD5 + length) — a
reference to bytes the catalog does not host (no Hatrac upload).
Builds a nested directory-structure dataset tree from the registered
files, and records the root source dataset as this execution's input
via a single Dataset_Execution row — O(1) regardless of file
count. Per-file File_Execution Input rows are intentionally not
written; find consumed files by traversing the dataset.
A file the run produced is a Hatrac-backed execution asset —
register those via asset_file_path + commit_output_assets,
never here. (Provenance contract: asset role is derived from context;
a File reference is an input by its nature.)
files is consumed lazily in batches of chunk_size — the inserts
are streamed, so a generator source (e.g.
FileSpec.create_filespecs over a large directory tree) never has to
be fully materialized in memory. Only the directory→RID map used to
build the directory-structure datasets is retained across the stream,
and it grows with the number of distinct directories, not the number
of files.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
files
|
Iterable[FileSpec]
|
File specifications containing MD5 checksum, length, and URL. May be any iterable, including a generator; it is consumed once. |
required |
execution_rid
|
RID
|
Execution RID to associate files with (required for provenance). |
required |
dataset_types
|
str | list[str] | None
|
One or more dataset type terms from File_Type vocabulary. |
None
|
description
|
str
|
Description applied to every non-root directory dataset.
The source folder each dataset represents is stored structurally
in the |
''
|
root_name
|
str | None
|
Optional name for the ingest-root dataset. When |
None
|
chunk_size
|
int
|
Number of File rows inserted per batch. Larger values mean fewer, bigger requests; smaller values bound per-request size and memory. A value at least as large as the input is a single batch (the historical behavior). |
500
|
Returns:
| Name | Type | Description |
|---|---|---|
Dataset |
'Dataset'
|
Dataset that represents the newly added files. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If file_types are invalid or execution_rid is not an execution record. |
Examples:
Add files via an execution: >>> with ml.create_execution(config) as exe: # doctest: +SKIP ... files = [FileSpec(url="path/to/file.txt", md5="abc123", length=1000)] ... dataset = exe.add_files(files, dataset_types="text")
Source code in src/deriva_ml/core/mixins/file.py
207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 | |
add_term
add_term(
table: str | Table,
term_name: str,
description: str,
synonyms: list[str] | None = None,
exists_ok: bool = True,
) -> VocabularyTermHandle
Adds a term to a vocabulary table.
Creates a new standardized term with description and optional synonyms in a vocabulary table. Can either create a new term or return an existing one if it already exists.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Vocabulary table to add term to (name or Table object). |
required |
term_name
|
str
|
Primary name of the term (must be unique within vocabulary). |
required |
description
|
str
|
Explanation of term's meaning and usage. |
required |
synonyms
|
list[str] | None
|
Alternative names for the term. |
None
|
exists_ok
|
bool
|
If True, return the existing term if found. If False, raise error. |
True
|
Returns:
| Name | Type | Description |
|---|---|---|
VocabularyTermHandle |
VocabularyTermHandle
|
Object representing the created or existing term, with methods to modify it in the catalog. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If a term exists and exists_ok=False, or if the table is not a vocabulary table. |
Examples:
Add a new tissue type: >>> term = ml.add_term( # doctest: +SKIP ... table="tissue_types", ... term_name="epithelial", ... description="Epithelial tissue type", ... synonyms=["epithelium"] ... ) >>> # Modify the term >>> term.description = "Updated description" # doctest: +SKIP >>> term.synonyms = ("epithelium", "epithelial_tissue") # doctest: +SKIP
Attempt to add an existing term: >>> term = ml.add_term("tissue_types", "epithelial", "...", exists_ok=True) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/vocabulary.py
111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 | |
add_visible_column
add_visible_column(
table: str | Table,
context: str,
column: str
| list[str]
| dict[str, Any],
position: int | None = None,
) -> list[Any]
Add a column to the visible-columns list for a specific context.
Convenience method for adding columns without replacing the entire
visible-columns annotation. Changes are staged until
apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
context
|
str
|
The context to modify (e.g., |
required |
column
|
str | list[str] | dict[str, Any]
|
Column to add. Can be:
- str: column name (e.g., |
required |
position
|
int | None
|
Position to insert at (0-indexed). If |
None
|
Returns:
| Type | Description |
|---|---|
list[Any]
|
The updated column list for the context. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If |
Example
ml.add_visible_column("Image", "compact", "Description") # doctest: +SKIP ml.add_visible_column("Image", "detailed", ["domain", "Image_Subject_fkey"], 1) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 | |
add_visible_foreign_key
add_visible_foreign_key(
table: str | Table,
context: str,
foreign_key: list[str]
| dict[str, Any],
position: int | None = None,
) -> list[Any]
Add a foreign key to the visible-foreign-keys list for a specific context.
Convenience method for adding related tables without replacing the
entire visible-foreign-keys annotation. Changes are staged until
apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
context
|
str
|
The context to modify (e.g., |
required |
foreign_key
|
list[str] | dict[str, Any]
|
Foreign key to add. Can be:
- list: inbound FK reference (e.g.,
|
required |
position
|
int | None
|
Position to insert at (0-indexed). If |
None
|
Returns:
| Type | Description |
|---|---|
list[Any]
|
The updated foreign key list for the context. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If |
Example
ml.add_visible_foreign_key("Subject", "detailed", ["domain", "Image_Subject_fkey"]) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 | |
apply_annotations
apply_annotations() -> None
Apply all staged annotation changes to the catalog.
Pushes any in-memory annotation changes to the live catalog. Must
be called after any sequence of set_* or add_*/remove_*
annotation calls to make changes visible in Chaise.
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the catalog is read-only or the apply call fails. |
Example
ml.set_display_annotation("Image", {"name": "Scan"}) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 | |
apply_catalog_annotations
apply_catalog_annotations(
navbar_brand_text: str = "ML Data Browser",
head_title: str = "Catalog ML",
) -> None
Apply catalog-level annotations including the navigation bar and display settings.
This method configures the Chaise web interface for the catalog. Chaise is Deriva's web-based data browser that provides a user-friendly interface for exploring and managing catalog data. This method sets up annotations that control how Chaise displays and organizes the catalog.
Navigation Bar Structure: The method creates a navigation bar with the following menus: - User Info: Links to Users, Groups, and RID Lease tables - Deriva-ML: Core ML tables (Workflow, Execution, Dataset, Dataset_Version, etc.) - WWW: Web content tables (Page, File) - {Domain Schema}: All domain-specific tables (excludes vocabularies and associations) - Vocabulary: All controlled vocabulary tables from both ML and domain schemas - Assets: All asset tables from both ML and domain schemas - Features: All feature tables with entries named "TableName:FeatureName" - Catalog Registry: Link to the ermrest registry - Documentation: Links to ML notebook instructions and Deriva-ML docs
Display Settings: - Underscores in table/column names displayed as spaces - System columns (RID) shown in compact and entry views - Default table set to Dataset - Faceting and record deletion enabled - Export configurations available to all users
Bulk Upload Configuration: Configures upload patterns for asset tables, enabling drag-and-drop file uploads through the Chaise interface.
Call this after creating the domain schema and all tables to initialize the catalog's web interface. The navigation menus are dynamically built based on the current schema structure, automatically organizing tables into appropriate categories.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
navbar_brand_text
|
str
|
Text displayed in the navigation bar brand area. |
'ML Data Browser'
|
head_title
|
str
|
Title displayed in the browser tab. |
'Catalog ML'
|
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP
After creating domain schema and tables...
ml.apply_catalog_annotations() # doctest: +SKIP
Or with custom branding:
ml.apply_catalog_annotations("My Project Browser", "My ML Project") # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1266 1267 1268 1269 1270 1271 1272 1273 1274 1275 1276 1277 1278 1279 1280 1281 1282 1283 1284 1285 1286 1287 1288 1289 1290 1291 1292 1293 1294 1295 1296 1297 1298 1299 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1312 1313 1314 1315 1316 1317 1318 1319 1320 1321 1322 1323 1324 | |
asset_record_class
asset_record_class(
asset_table_name: str,
) -> type
Create a dynamically generated Pydantic model for an asset table's metadata.
The returned class is a subclass of AssetRecord with fields derived from the asset table's metadata columns (non-system, non-standard-asset columns). Fields are typed according to their database column type, and nullable columns are Optional.
Follows the same pattern as Feature.feature_record_class().
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_table_name
|
str
|
Name of the asset table (e.g., "Image", "Model"). |
required |
Returns:
| Type | Description |
|---|---|
type
|
An AssetRecord subclass with validated fields matching the table's metadata. |
Example
ImageAsset = ml.asset_record_class("Image") # doctest: +SKIP record = ImageAsset(Subject="2-DEF", Acquisition_Date="2026-01-15") # doctest: +SKIP path = exe.asset_file_path("Image", "scan.jpg", metadata=record) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 | |
audit_provenance
audit_provenance() -> (
"ProvenanceAuditReport"
)
Run the read-only provenance audit over the whole catalog.
Surfaces every violation of the complete-provenance predicate, plus a separate known-degraded report of compliant-but-thin provenance (sentinel attributions). It is advisory and read-only — it detects; it never mutates state, fails a build, or blocks a commit (provenance contract §Audit, Goal 4). Run it on demand or on a schedule as a per-catalog health report.
Returns:
| Type | Description |
|---|---|
'ProvenanceAuditReport'
|
class: |
'ProvenanceAuditReport'
|
with |
'ProvenanceAuditReport'
|
surfaced for visibility) finding lists. |
Example
report = ml.audit_provenance() # doctest: +SKIP print(report.summary()) # doctest: +SKIP for v in report.violations: # doctest: +SKIP ... print(v)
Source code in src/deriva_ml/core/mixins/execution.py
133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 | |
bag_info
bag_info(
dataset: "DatasetSpec",
) -> dict[str, Any]
Get comprehensive info about a dataset bag: size, contents, and cache status.
Combines the size estimate with local cache status. Use this to decide whether to prefetch a bag before running an experiment.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset
|
'DatasetSpec'
|
Specification of the dataset, including version and optional exclude_tables. |
required |
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
dict with keys: - tables: dict mapping table name to {row_count, is_asset, asset_bytes} - total_rows, total_asset_bytes, total_asset_size - cache_status: one of "not_cached", "cached_materialized", "cached_holey" - cache_path: local path to cached bag (if cached), else None |
Source code in src/deriva_ml/core/mixins/dataset.py
501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 | |
bootstrap_config
bootstrap_config(
*,
kinds: list[str] | None = None,
dataset_type_filter: list[str]
| None = None,
) -> BootstrapReport
Suggest config entries by reading the catalog.
Walks the catalog and produces structured :class:BootstrapSuggestion
objects -- one per dataset / asset / workflow row a fresh
project's src/configs/ might want to pin. Does NOT write
files. The skill prose layer formats the suggestions into the
right config file (per-skill ownership of "which file" --
dataset-lifecycle for datasets, work-with-assets for
assets, write-hydra-config for the umbrella).
Three use cases:
- New project, empty configs/. Run unfiltered to see every candidate entry; pick the subset that's relevant.
- Catalog clone or environment switch. Bootstrap to repoint configs at the new catalog, then validate to catch any stragglers.
- Incremental update. Pass
kinds=["datasets"]to see fresh dataset suggestions after a release without enumerating assets / workflows.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
kinds
|
list[str] | None
|
Which config groups to suggest entries for. Default
is all four ( |
None
|
dataset_type_filter
|
list[str] | None
|
When suggesting datasets, restrict
to these |
None
|
Returns:
| Name | Type | Description |
|---|---|---|
A |
BootstrapReport
|
class: |
BootstrapReport
|
|
|
BootstrapReport
|
specific entities weren't suggested. |
Example
One-shot bootstrap::
>>> report = ml.bootstrap_config() # doctest: +SKIP
>>> for s in report.suggestions: # doctest: +SKIP
... print(s.kind, s.config_name, s.spec_string)
Source code in src/deriva_ml/core/mixins/dataset.py
999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 | |
cache_dataset
cache_dataset(
dataset: "DatasetSpec",
materialize: bool = True,
) -> dict[str, Any]
Download a dataset bag into the local cache without creating an execution.
Use this to warm the cache before running experiments. No execution or provenance records are created.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset
|
'DatasetSpec'
|
Specification of the dataset, including version and
optional exclude_tables. Concurrency is taken from the spec:
|
required |
materialize
|
bool
|
If True (default), download all asset files. If False, download only table metadata. |
True
|
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
dict with bag_info results after caching. |
Source code in src/deriva_ml/core/mixins/dataset.py
650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 | |
cache_table
cache_table(
table_name: str, force: bool = False
) -> "pd.DataFrame"
Fetch a table from the catalog and cache locally as SQLite.
On first call, fetches all rows from the catalog and stores in the
working data cache. Subsequent calls return the cached data without
contacting the catalog. Use force=True to re-fetch.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table_name
|
str
|
Name of the table to fetch (e.g., "Subject", "Image"). |
required |
force
|
bool
|
If True, re-fetch even if already cached. |
False
|
Returns:
| Type | Description |
|---|---|
'pd.DataFrame'
|
DataFrame with the table contents. |
Example::
subjects = ml.cache_table("Subject")
print(f"{len(subjects)} subjects")
# Second call returns cached data instantly
subjects = ml.cache_table("Subject")
Source code in src/deriva_ml/core/base.py
1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 | |
catalog_snapshot
catalog_snapshot(
version_snapshot: str,
) -> Self
Return a new DerivaML instance connected to a specific catalog snapshot.
Catalog snapshots provide a read-only, point-in-time view of the catalog. The snapshot identifier is typically obtained from a dataset version record.
Every connection-shaping kwarg the original instance was
constructed with (working_dir, cache_dir,
domain_schemas, default_schema, s3_bucket,
use_minid, credential, mode, ml_schema,
project_name, clean_execution_dir, plus the two
logging levels) is forwarded to the snapshot instance.
Without this forwarding, the snapshot would silently default
working_dir to ~/deriva_ml even when the user
constructed self with an explicit shared-tree path, and
would re-fetch credentials and re-detect domain schemas
(which can pick differently from the snapshot than the live
catalog did) — both observable behaviour drifts.
The snapshot reuses this instance's already-parsed schema
(self._schema_json) rather than re-fetching /schema — a
snapshot's schema is structurally identical to the live
catalog's. The constructed instance is memoized by
version_snapshot so repeated calls share one object.
Precondition: the snapshot's schema must match the live catalog's. This holds for deriva-ml's use (pinning a recent dataset-version snaptime on a catalog whose schema has not been migrated since). Do not use for a snapshot taken before a schema migration — its structure would differ from live.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
version_snapshot
|
str
|
Snapshot identifier string (e.g., |
required |
Returns:
| Type | Description |
|---|---|
Self
|
A new DerivaML instance connected to the specified catalog snapshot, |
Self
|
inheriting every connection-shaping kwarg from |
Note
The reused schema_json can lag the live catalog within a
session — e.g. tables created after this connection was opened
are absent from the held model. Any caller that mixes this
snapshot's pathBuilder() (held, possibly-stale model) with a
freshly-fetched deriva-py model (e.g. a CatalogBagBuilder
walk that calls _get_model()) must build its path builder
from the same fresh model via
datapath.from_model(snapshot.catalog, model) — otherwise a
KeyError is raised on tables the held model lacks.
Source code in src/deriva_ml/core/base.py
878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 | |
chaise_url
chaise_url(
table: RID | Table | str,
) -> str
Generates Chaise web interface URL.
Chaise is Deriva's web interface for data exploration. This method creates a URL that directly links to the specified table or record.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
RID | Table | str
|
Table to generate URL for (name, Table object, or RID). |
required |
Returns:
| Name | Type | Description |
|---|---|---|
str |
str
|
URL in format: https://{host}/chaise/recordset/#{catalog}/{schema}:{table} |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If table or RID cannot be found. |
Examples:
Using table name: >>> ml.chaise_url("experiment_table") # doctest: +SKIP 'https://deriva.org/chaise/recordset/#1/schema:experiment_table'
Using RID: >>> ml.chaise_url("1-abc123") # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 | |
cite
cite(
entity: Dict[str, Any] | str,
current: bool = False,
) -> str
Generates citation URL for an entity.
Creates a URL that can be used to reference a specific entity in the catalog. By default, includes the catalog snapshot time to ensure version stability (permanent citation). With current=True, returns a URL to the current state.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
entity
|
Dict[str, Any] | str
|
Either a RID string or a dictionary containing entity data with a 'RID' key. |
required |
current
|
bool
|
If True, return URL to current catalog state (no snapshot). If False (default), return permanent citation URL with snapshot time. |
False
|
Returns:
| Name | Type | Description |
|---|---|---|
str |
str
|
Citation URL. Format depends on |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If an entity doesn't exist or lacks a RID. |
Examples:
Permanent citation (default): >>> url = ml.cite("1-abc123") # doctest: +SKIP >>> print(url) # doctest: +SKIP 'https://deriva.org/id/1/1-abc123@2024-01-01T12:00:00'
Current catalog URL: >>> url = ml.cite("1-abc123", current=True) # doctest: +SKIP >>> print(url) # doctest: +SKIP 'https://deriva.org/id/1/1-abc123'
Using a dictionary: >>> url = ml.cite({"RID": "1-abc123"}) # doctest: +SKIP
Dry-run sentinel — no catalog round-trip, no clickable link: >>> url = ml.cite("0000") # doctest: +SKIP >>> print(url) # doctest: +SKIP 'dry-run (rid=0000)'
Source code in src/deriva_ml/core/base.py
1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 | |
clean_execution_dirs
clean_execution_dirs(
older_than_days: int | None = None,
exclude_rids: list[str]
| None = None,
) -> dict[str, int]
Clean up execution working directories.
Removes execution output directories from the local working directory. Use this to free up disk space from completed or orphaned executions.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
older_than_days
|
int | None
|
If provided, only remove directories older than this many days. If None, removes all execution directories (except excluded). |
None
|
exclude_rids
|
list[str] | None
|
List of execution RIDs to preserve (never remove). |
None
|
Returns:
| Type | Description |
|---|---|
dict[str, int]
|
dict with keys: - 'dirs_removed': Number of directories removed - 'bytes_freed': Total bytes freed - 'errors': Number of removal errors |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP
Clean all execution dirs older than 30 days
result = ml.clean_execution_dirs(older_than_days=30) # doctest: +SKIP print(f"Freed {result['bytes_freed'] / 1e9:.2f} GB") # doctest: +SKIP
Clean all except specific executions
result = ml.clean_execution_dirs(exclude_rids=['1-ABC', '1-DEF']) # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1781 1782 1783 1784 1785 1786 1787 1788 1789 1790 1791 1792 1793 1794 1795 1796 1797 1798 1799 1800 1801 1802 1803 1804 1805 1806 1807 1808 1809 1810 1811 1812 1813 1814 1815 1816 1817 1818 1819 1820 1821 1822 1823 1824 1825 1826 1827 1828 1829 1830 1831 1832 1833 1834 1835 1836 1837 1838 1839 1840 1841 1842 1843 1844 1845 1846 1847 1848 1849 1850 1851 1852 | |
clear_cache
clear_cache(
older_than_days: int | None = None,
) -> dict[str, int]
Clear the dataset cache directory.
Removes cached dataset bags and assets. Bags are removed through the bag-cache index (index row and on-disk directory together), so the index never references a removed bag.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
older_than_days
|
int | None
|
If provided, only remove cache entries older than this
many days (bags age by their recorded |
None
|
Returns:
| Name | Type | Description |
|---|---|---|
dict |
dict[str, int]
|
Statistics about the cleanup: - 'files_removed': Number of files removed - 'dirs_removed': Number of directories removed - 'bytes_freed': Total bytes freed - 'errors': Number of errors encountered |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP stats = ml.clear_cache(older_than_days=30) # doctest: +SKIP print(f"Freed {stats['bytes_freed'] / 1e6:.1f} MB") # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1670 1671 1672 1673 1674 1675 1676 1677 1678 1679 1680 1681 1682 1683 1684 1685 1686 1687 1688 1689 1690 1691 1692 1693 1694 1695 1696 | |
clear_vocabulary_cache
clear_vocabulary_cache(
table: str | Table | None = None,
) -> None
Clear the vocabulary term cache.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table | None
|
If provided, only clear cache for this specific vocabulary table. If None, clear the entire cache. |
None
|
Source code in src/deriva_ml/core/mixins/vocabulary.py
71 72 73 74 75 76 77 78 79 80 81 82 83 84 | |
commit_pending_executions
commit_pending_executions(
*,
execution_rids: "list[RID] | None" = None,
clean_folder: bool = False,
) -> "UploadReport"
Batch-commit pending output assets for one or more executions.
ADR-0009's batch upload entry point. For each requested
execution, resumes it from the workspace registry and calls
:meth:Execution.commit_output_assets, which brackets the
bag-commit with the full lifecycle (Pending_Upload →
Uploaded transition, Upload_Duration recording, asset
description writes, optional working-folder cleanup).
Failure isolation is per-execution: an exception while
committing execution A does not skip execution B; both
outcomes appear in the returned :class:UploadReport. The
blocking call returns even when one or more executions
failed; callers check report.total_failed and
report.errors for diagnosis.
This is the engine behind the deriva-ml-upload CLI.
Online mode only.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
execution_rids
|
'list[RID] | None'
|
List of RIDs, or |
None
|
clean_folder
|
bool
|
Forwarded to
:meth: |
False
|
Returns:
| Type | Description |
|---|---|
'UploadReport'
|
UploadReport aggregating per-execution outcomes. Successful |
'UploadReport'
|
executions contribute their per-(schema, table) counts to |
'UploadReport'
|
|
'UploadReport'
|
|
'UploadReport'
|
to |
'UploadReport'
|
|
Example
report = ml.commit_pending_executions() # doctest: +SKIP print(f"{report.total_uploaded} uploaded, " # doctest: +SKIP ... f"{report.total_failed} failed")
Source code in src/deriva_ml/core/mixins/execution.py
1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 | |
create_asset
create_asset(
asset_name: str,
column_defs: Iterable[
ColumnDefinition
]
| None = None,
fkey_defs: Iterable[
ColumnDefinition
]
| None = None,
referenced_tables: Iterable[Table]
| None = None,
comment: str = "",
schema: str | None = None,
update_navbar: bool = True,
) -> Table
Create a new asset table in the catalog.
Defines a Chaise-compatible asset table (Filename, URL, Length, MD5,
Description, plus system columns) with optional additional metadata
columns and foreign-key references. Registers the asset type in the
Asset_Type vocabulary and optionally updates the Chaise navigation
bar.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_name
|
str
|
Name for the new asset table, e.g. |
required |
column_defs
|
Iterable[ColumnDefinition] | None
|
Extra metadata columns beyond the standard asset
columns. Each is a |
None
|
fkey_defs
|
Iterable[ColumnDefinition] | None
|
Foreign-key definitions from the asset table to other tables (e.g., linking images to a subject table). |
None
|
referenced_tables
|
Iterable[Table] | None
|
Tables that the new asset table should reference
via FKs. Convenience alternative to |
None
|
comment
|
str
|
Human-readable description of the asset table stored as the table comment in the catalog. |
''
|
schema
|
str | None
|
Schema in which to create the table. Defaults to
|
None
|
update_navbar
|
bool
|
If |
True
|
Returns:
| Type | Description |
|---|---|
Table
|
The newly created |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If a table named |
DerivaMLSchemaError
|
If |
Example
from deriva.core.typed import Column, builtin_types # doctest: +SKIP ml.create_asset( # doctest: +SKIP ... "ScanImage", # doctest: +SKIP ... comment="MRI scan images", # doctest: +SKIP ... ) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | |
create_asset_table
create_asset_table(
asset_name: str,
additional_columns: Sequence[
ColumnDefinition
] = (),
comment: str | None = None,
schema: str | None = None,
use_hatrac: bool = True,
update_navbar: bool = True,
) -> Table
Creates an asset table with the canonical DerivaML asset shape.
One call builds everything an asset table needs, so the shape can
never drift from the canonical form (validation-by-construction --
the result always satisfies model.is_asset):
- The five standard hatrac columns:
URL,Filename,Length,MD5,Description(with the standard NOT NULL constraints and theassetannotation onURL). - The
<asset_name>_Asset_Typeassociation to the deriva-mlAsset_Typevocabulary (an asset can carry multiple type tags, e.g.Model_File+Output_File). - The
<asset_name>_Executionassociation toExecution, carrying theAsset_RoleFK (Input/Output) that the execution upload machinery writes. - The standard Chaise display annotations for asset tables.
This replaces the manual recipe (generic create_table with
hand-written hatrac columns) that was verbose and easy to get
subtly wrong (issue #74).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_name
|
str
|
Name for the new asset table. Must be a valid SQL identifier. |
required |
additional_columns
|
Sequence[ColumnDefinition]
|
Optional domain-specific columns appended to
the standard hatrac shape (e.g. a |
()
|
comment
|
str | None
|
Description of the asset table's purpose. |
None
|
schema
|
str | None
|
Schema name to create the table in. If None, uses the domain schema. |
None
|
use_hatrac
|
bool
|
When True (default) the |
True
|
update_navbar
|
bool
|
If True (default), refresh the navigation bar to
include the new table. Set to False during batch creation,
then call |
True
|
Returns:
| Name | Type | Description |
|---|---|---|
Table |
Table
|
ERMrest table object for the newly created asset table. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If |
Examples:
Create an asset table for raw scanner output:
>>> from deriva_ml import ColumnDefinition, BuiltinTypes
>>> table = ml.create_asset_table( # doctest: +SKIP
... "Scan_File",
... additional_columns=[
... ColumnDefinition(name="Scanner_Model", type=BuiltinTypes.text),
... ],
... comment="Raw scanner output files.",
... )
>>> ml.model.is_asset("Scan_File") # doctest: +SKIP
True
Source code in src/deriva_ml/core/base.py
1394 1395 1396 1397 1398 1399 1400 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1416 1417 1418 1419 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469 1470 1471 1472 1473 1474 1475 1476 1477 1478 1479 1480 1481 1482 1483 1484 1485 1486 1487 1488 1489 | |
create_execution
create_execution(
configuration: "ExecutionConfiguration | None" = None,
*,
datasets: "list[DatasetSpec | str] | None" = None,
assets: "list[AssetSpec | str] | None" = None,
workflow: "Workflow | RID | str | None" = None,
description: "str | None" = None,
dry_run: bool = False,
) -> "Execution"
Create an execution environment.
Initializes a local compute environment for executing an ML or
analytic routine. Accepts either a pre-built
:class:ExecutionConfiguration (the config-object form) or
individual keyword arguments that the method assembles into an
ExecutionConfiguration (the kwargs form). Mixing the two
forms is rejected with TypeError — pick one.
Creating executions requires online mode because the Execution RID is server-assigned.
Side effects:
- Downloads datasets specified in the configuration to the cache directory. If no version is specified, creates a new minor version for the dataset.
- Downloads any execution assets to the working directory.
- Creates an execution record in the catalog (unless
dry_run=True).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
configuration
|
'ExecutionConfiguration | None'
|
A pre-built ExecutionConfiguration. If this
is provided, all of the kwargs below (except
|
None
|
datasets
|
'list[DatasetSpec | str] | None'
|
Kwargs form only. List of :class: |
None
|
assets
|
'list[AssetSpec | str] | None'
|
Kwargs form only. List of :class: |
None
|
workflow
|
'Workflow | RID | str | None'
|
A :class: |
None
|
description
|
'str | None'
|
Kwargs form only. Human-readable description of the execution. |
None
|
dry_run
|
bool
|
If True, skip creating catalog records and uploading results. |
False
|
Returns:
| Name | Type | Description |
|---|---|---|
An |
'Execution'
|
class: |
'Execution'
|
lifecycle. |
Raises:
| Type | Description |
|---|---|
TypeError
|
If |
DerivaMLOfflineError
|
If the current connection mode is
:attr: |
Example
Config-object form::
>>> config = ExecutionConfiguration( # doctest: +SKIP
... workflow=workflow,
... description="Process samples",
... datasets=[DatasetSpec(rid="4HM", version="1.0.0")],
... )
>>> with ml.create_execution(config) as execution: # doctest: +SKIP
... # Run analysis
... pass
>>> execution.commit_output_assets() # doctest: +SKIP
Kwargs form (equivalent)::
>>> with ml.create_execution( # doctest: +SKIP
... datasets=["4HM@1.0.0"],
... workflow=workflow,
... description="Process samples",
... ) as execution:
... # Run analysis
... pass
Source code in src/deriva_ml/core/mixins/execution.py
158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 | |
create_feature
create_feature(
target_table: Table | str,
feature_name: str,
terms: list[Table | str]
| None = None,
assets: list[Table | str]
| None = None,
metadata: list[
ColumnDefinition
| Table
| Key
| str
]
| None = None,
optional: list[str] | None = None,
comment: str = "",
update_navbar: bool = True,
) -> type[FeatureRecord]
Creates a new feature definition.
A feature represents a measurable property or characteristic that can be associated with records in the target table. Features can include vocabulary terms, asset references, and additional metadata.
Side Effects: This method dynamically creates: 1. A new association table in the domain schema to store feature values 2. A Pydantic model class (subclass of FeatureRecord) for creating validated feature instances
The returned Pydantic model class provides type-safe construction of feature records with automatic validation of values against the feature's definition (vocabulary terms, asset references, etc.). Use this class to create feature instances that can be inserted into the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
target_table
|
Table | str
|
Table to associate the feature with (name or Table object). |
required |
feature_name
|
str
|
Unique name for the feature within the target table. |
required |
terms
|
list[Table | str] | None
|
Optional vocabulary tables/names whose terms can be used as feature values. |
None
|
assets
|
list[Table | str] | None
|
Optional asset tables/names that can be referenced by this feature. |
None
|
metadata
|
list[ColumnDefinition | Table | Key | str] | None
|
Optional columns, tables, or keys to include in a feature definition. |
None
|
optional
|
list[str] | None
|
Column names that are not required when creating feature instances. |
None
|
comment
|
str
|
Description of the feature's purpose and usage. |
''
|
update_navbar
|
bool
|
If True (default), automatically updates the navigation bar to include the new feature table. Set to False during batch feature creation to avoid redundant updates, then call apply_catalog_annotations() once at the end. |
True
|
Returns:
| Type | Description |
|---|---|
type[FeatureRecord]
|
type[FeatureRecord]: A dynamically generated Pydantic model class for creating validated feature instances. The class has fields corresponding to the feature's terms, assets, and metadata columns. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If a feature definition is invalid or conflicts with existing features. |
Examples:
Create a feature with confidence score: >>> DiagnosisFeature = ml.create_feature( # doctest: +SKIP ... target_table="Image", ... feature_name="Diagnosis", ... terms=["Diagnosis_Type"], ... metadata=[ColumnDefinition(name="confidence", type=BuiltinTypes.float4)], ... comment="Clinical diagnosis label" ... ) >>> # Use the returned class to create validated feature instances >>> record = DiagnosisFeature( # doctest: +SKIP ... Image="1-ABC", # Target record RID ... Diagnosis_Type="Normal", # Vocabulary term ... confidence=0.95, ... Execution="2-XYZ" # Execution that produced this value ... )
Source code in src/deriva_ml/core/mixins/feature.py
63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 | |
create_table
create_table(
table: TableDefinition,
schema: str | None = None,
update_navbar: bool = True,
) -> Table
Creates a new table in the domain schema.
Creates a table using the provided TableDefinition object, which specifies the table structure including columns, keys, and foreign key relationships. The table is created in the domain schema associated with this DerivaML instance.
Required Classes: Import the following classes from deriva_ml to define tables:
TableDefinition: Defines the complete table structureColumnDefinition: Defines individual columns with types and constraintsKeyDefinition: Defines unique key constraints (optional)ForeignKeyDefinition: Defines foreign key relationships to other tables (optional)BuiltinTypes: Enum of available column data types
Available Column Types (BuiltinTypes enum):
text, int2, int4, int8, float4, float8, boolean,
date, timestamp, timestamptz, json, jsonb, markdown,
ermrest_uri, ermrest_rid, ermrest_rcb, ermrest_rmb,
ermrest_rct, ermrest_rmt
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
TableDefinition
|
A TableDefinition object containing the complete specification of the table to create. |
required |
update_navbar
|
bool
|
If True (default), automatically updates the navigation bar to include the new table. Set to False during batch table creation to avoid redundant updates, then call apply_catalog_annotations() once at the end. |
True
|
Returns:
| Name | Type | Description |
|---|---|---|
Table |
Table
|
The newly created ERMRest table object. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If table creation fails or the definition is invalid. |
Examples:
Simple table with basic columns:
>>> from deriva_ml import TableDefinition, ColumnDefinition, BuiltinTypes # doctest: +SKIP
>>>
>>> table_def = TableDefinition( # doctest: +SKIP
... name="Experiment",
... column_defs=[
... ColumnDefinition(name="Name", type=BuiltinTypes.text, nullok=False),
... ColumnDefinition(name="Date", type=BuiltinTypes.date),
... ColumnDefinition(name="Description", type=BuiltinTypes.markdown),
... ColumnDefinition(name="Score", type=BuiltinTypes.float4),
... ],
... comment="Records of experimental runs"
... )
>>> experiment_table = ml.create_table(table_def) # doctest: +SKIP
Table with foreign key to another table:
>>> from deriva_ml import ( # doctest: +SKIP
... TableDefinition, ColumnDefinition, ForeignKeyDefinition, BuiltinTypes
... )
>>>
>>> # Create a Sample table that references Subject
>>> sample_def = TableDefinition( # doctest: +SKIP
... name="Sample",
... column_defs=[
... ColumnDefinition(name="Name", type=BuiltinTypes.text, nullok=False),
... ColumnDefinition(name="Subject", type=BuiltinTypes.text, nullok=False),
... ColumnDefinition(name="Collection_Date", type=BuiltinTypes.date),
... ],
... fkey_defs=[
... ForeignKeyDefinition(
... colnames=["Subject"],
... pk_sname=ml.default_schema, # Schema of referenced table
... pk_tname="Subject", # Name of referenced table
... pk_colnames=["RID"], # Column(s) in referenced table
... on_delete="CASCADE", # Delete samples when subject deleted
... )
... ],
... comment="Biological samples collected from subjects"
... )
>>> sample_table = ml.create_table(sample_def) # doctest: +SKIP
Table with unique key constraint:
>>> from deriva_ml import ( # doctest: +SKIP
... TableDefinition, ColumnDefinition, KeyDefinition, BuiltinTypes
... )
>>>
>>> protocol_def = TableDefinition( # doctest: +SKIP
... name="Protocol",
... column_defs=[
... ColumnDefinition(name="Name", type=BuiltinTypes.text, nullok=False),
... ColumnDefinition(name="Version", type=BuiltinTypes.text, nullok=False),
... ColumnDefinition(name="Description", type=BuiltinTypes.markdown),
... ],
... key_defs=[
... KeyDefinition(
... colnames=["Name", "Version"],
... constraint_names=[["myschema", "Protocol_Name_Version_key"]],
... comment="Each protocol name+version must be unique"
... )
... ],
... comment="Experimental protocols with versioning"
... )
>>> protocol_table = ml.create_table(protocol_def) # doctest: +SKIP
Batch creation without navbar updates:
>>> ml.create_table(table1_def, update_navbar=False) # doctest: +SKIP
>>> ml.create_table(table2_def, update_navbar=False) # doctest: +SKIP
>>> ml.create_table(table3_def, update_navbar=False) # doctest: +SKIP
>>> ml.apply_catalog_annotations() # Update navbar once at the end # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1491 1492 1493 1494 1495 1496 1497 1498 1499 1500 1501 1502 1503 1504 1505 1506 1507 1508 1509 1510 1511 1512 1513 1514 1515 1516 1517 1518 1519 1520 1521 1522 1523 1524 1525 1526 1527 1528 1529 1530 1531 1532 1533 1534 1535 1536 1537 1538 1539 1540 1541 1542 1543 1544 1545 1546 1547 1548 1549 1550 1551 1552 1553 1554 1555 1556 1557 1558 1559 1560 1561 1562 1563 1564 1565 1566 1567 1568 1569 1570 1571 1572 1573 1574 1575 1576 1577 1578 1579 1580 1581 1582 1583 1584 1585 1586 1587 1588 1589 1590 1591 1592 1593 1594 1595 1596 1597 1598 1599 1600 1601 1602 1603 1604 1605 1606 1607 1608 1609 1610 1611 1612 1613 1614 1615 | |
create_vocabulary
create_vocabulary(
vocab_name: str,
comment: str = "",
schema: str | None = None,
update_navbar: bool = True,
) -> Table
Creates a controlled vocabulary table.
A controlled vocabulary table maintains a list of standardized terms and their definitions. Each term can have synonyms and descriptions to ensure consistent terminology usage across the dataset.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
vocab_name
|
str
|
Name for the new vocabulary table. Must be a valid SQL identifier. |
required |
comment
|
str
|
Description of the vocabulary's purpose and usage. Defaults to empty string. |
''
|
schema
|
str | None
|
Schema name to create the table in. If None, uses domain_schema. |
None
|
update_navbar
|
bool
|
If True (default), automatically updates the navigation bar to include the new vocabulary table. Set to False during batch table creation to avoid redundant updates, then call apply_catalog_annotations() once at the end. |
True
|
Returns:
| Name | Type | Description |
|---|---|---|
Table |
Table
|
ERMRest table object representing the newly created vocabulary table. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If vocab_name is invalid or already exists. |
Examples:
Create a vocabulary for tissue types:
>>> table = ml.create_vocabulary( # doctest: +SKIP
... vocab_name="tissue_types",
... comment="Standard tissue classifications",
... schema="bio_schema"
... )
Create multiple vocabularies without updating navbar until the end:
>>> ml.create_vocabulary("Species", update_navbar=False) # doctest: +SKIP
>>> ml.create_vocabulary("Tissue_Type", update_navbar=False) # doctest: +SKIP
>>> ml.apply_catalog_annotations() # Update navbar once # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1326 1327 1328 1329 1330 1331 1332 1333 1334 1335 1336 1337 1338 1339 1340 1341 1342 1343 1344 1345 1346 1347 1348 1349 1350 1351 1352 1353 1354 1355 1356 1357 1358 1359 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380 1381 1382 1383 1384 1385 1386 1387 1388 1389 1390 1391 1392 | |
create_workflow
create_workflow(
name: str,
workflow_type: str | list[str],
description: str = "",
) -> Workflow
Creates a new workflow definition.
Creates a Workflow object that represents a computational process or analysis pipeline. The workflow type(s) must be terms from the controlled vocabulary. This method is typically used to define new analysis workflows before execution.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name
|
str
|
Name of the workflow. |
required |
workflow_type
|
str | list[str]
|
Type(s) of workflow (must exist in workflow_type vocabulary). Can be a single string or a list of strings. |
required |
description
|
str
|
Description of what the workflow does. |
''
|
Returns:
| Name | Type | Description |
|---|---|---|
Workflow |
Workflow
|
New workflow object ready for registration. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If any workflow_type is not in the vocabulary. |
Examples:
>>> workflow = ml.create_workflow(
... name="RNA Analysis",
... workflow_type="python_notebook",
... description="RNA sequence analysis pipeline"
... )
>>> rid = ml._add_workflow(workflow)
Multiple types::
>>> workflow = ml.create_workflow( # doctest: +SKIP
... name="Training Pipeline",
... workflow_type=["Training", "Embedding"],
... description="Combined training and embedding pipeline"
... )
Source code in src/deriva_ml/core/mixins/workflow.py
371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 | |
define_association
define_association(
associates: list,
metadata: list | None = None,
table_name: str | None = None,
comment: str | None = None,
**kwargs,
) -> dict
Build an association table definition with vocab-aware key selection.
Creates a table definition that links two or more tables via an association (many-to-many) table. Non-vocabulary tables automatically use RID as the foreign key target, while vocabulary tables use their Name key.
Use with create_table() to create the association table in the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
associates
|
list
|
Tables to associate. Each item can be: - A Table object - A (name, Table) tuple to customize the column name - A (name, nullok, Table) tuple for nullable references - A Key object for explicit key selection |
required |
metadata
|
list | None
|
Additional metadata columns or reference targets. |
None
|
table_name
|
str | None
|
Name for the association table. Auto-generated if omitted. |
None
|
comment
|
str | None
|
Comment for the association table. |
None
|
**kwargs
|
Additional arguments passed to Table.define_association. |
{}
|
Returns:
| Type | Description |
|---|---|
dict
|
Table definition dict suitable for |
Example::
# Associate Image with Subject (many-to-many)
image_table = ml.model.name_to_table("Image")
subject_table = ml.model.name_to_table("Subject")
assoc_def = ml.define_association(
associates=[image_table, subject_table],
comment="Links images to subjects",
)
ml.create_table(assoc_def)
Source code in src/deriva_ml/core/base.py
1617 1618 1619 1620 1621 1622 1623 1624 1625 1626 1627 1628 1629 1630 1631 1632 1633 1634 1635 1636 1637 1638 1639 1640 1641 1642 1643 1644 1645 1646 1647 1648 1649 1650 1651 1652 1653 1654 1655 1656 1657 1658 1659 1660 1661 1662 1663 1664 | |
delete_cached_asset
delete_cached_asset(
rid: str, md5: str | None = None
) -> dict[str, int]
Delete cached copies of an input asset.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
rid
|
str
|
Asset RID whose cache entries to remove. |
required |
md5
|
str | None
|
When given, only the copy with that checksum;
|
None
|
Returns:
| Type | Description |
|---|---|
dict[str, int]
|
|
dict[str, int]
|
nothing matched (idempotent). |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP ml.delete_cached_asset('2-XYZ') # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1915 1916 1917 1918 1919 1920 1921 1922 1923 1924 1925 1926 1927 1928 1929 1930 1931 1932 1933 | |
delete_cached_bag
delete_cached_bag(
dataset_rid: str,
version: str | None = None,
) -> dict[str, int]
Delete a dataset's cached bag(s).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset_rid
|
str
|
Dataset RID whose cached bags to remove. |
required |
version
|
str | None
|
When given, only the bag for that version;
|
None
|
Returns:
| Type | Description |
|---|---|
dict[str, int]
|
|
dict[str, int]
|
dataset isn't cached (idempotent). |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP ml.delete_cached_bag('1-ABC', version='1.2.0') # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1875 1876 1877 1878 1879 1880 1881 1882 1883 1884 1885 1886 1887 1888 1889 1890 1891 1892 1893 1894 | |
delete_dataset
delete_dataset(
dataset: "Dataset",
recurse: bool = False,
) -> None
Soft-delete a dataset by marking it as deleted in the catalog.
Sets the Deleted flag on the dataset record. The dataset's data is
preserved but it will no longer appear in normal queries (e.g.,
find_datasets()). The dataset cannot be deleted if it is currently
nested inside a parent dataset.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset
|
Dataset
|
The dataset to delete. |
required |
recurse
|
bool
|
If True, also soft-delete all nested child datasets. If False (default), only this dataset is marked as deleted. |
False
|
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the dataset RID is not a valid dataset, or if the dataset is nested inside a parent dataset. |
Example
ds = ml.lookup_dataset("1-ABC") # doctest: +SKIP ml.delete_dataset(ds, recurse=False) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/dataset.py
214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 | |
delete_feature
delete_feature(
table: Table | str,
feature_name: str,
) -> bool
Removes a feature definition and its data.
Deletes the feature and its implementation table from the catalog. This operation cannot be undone and will remove all feature values associated with this feature.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
Table | str
|
The table containing the feature, either as name or Table object. |
required |
feature_name
|
str
|
Name of the feature to delete. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
bool |
bool
|
True if the feature was successfully deleted, False if it didn't exist. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If deletion fails due to constraints or permissions. |
Example
success = ml.delete_feature("samples", "obsolete_feature") # doctest: +SKIP print("Deleted" if success else "Not found") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/feature.py
261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 | |
delete_term
delete_term(
table: str | Table, term_name: str
) -> None
Delete a term from a vocabulary table.
Removes a term from the vocabulary. The term must not be in use by any records in the catalog (e.g., no datasets using this dataset type, no assets using this asset type).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Vocabulary table containing the term (name or Table object). |
required |
term_name
|
str
|
Primary name of the term to delete. |
required |
Raises:
| Type | Description |
|---|---|
DerivaMLInvalidTerm
|
If the term doesn't exist in the vocabulary. |
DerivaMLException
|
If the term is currently in use by other records. |
Example
ml.delete_term("Dataset_Type", "Obsolete_Type") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/vocabulary.py
400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 | |
diff_schema
diff_schema() -> 'SchemaDiff'
Return the structural diff between the cached and live schemas.
Online mode only. Fetches the live catalog's /schema
payload, compares it against the cached copy with
:func:~deriva_ml.core.schema_diff._compute_diff, and returns
the result. The returned :class:SchemaDiff may be empty
(no drift) — callers should check diff.is_empty() rather
than truthiness.
Unlike :meth:pin_schema, this method never modifies the
cache and never logs a warning; it is a pure inspection
operation.
Returns:
| Name | Type | Description |
|---|---|---|
A |
'SchemaDiff'
|
class: |
Raises:
| Type | Description |
|---|---|
DerivaMLOfflineError
|
If called in offline mode. |
FileNotFoundError
|
If the workspace has no cache file. |
Source code in src/deriva_ml/core/base.py
735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 | |
download_dataset_bag
download_dataset_bag(
dataset: DatasetSpec,
) -> "DatasetBag"
Downloads a dataset to the local filesystem.
Downloads a dataset specified by DatasetSpec to the local filesystem. If the catalog has s3_bucket configured and use_minid is enabled, the bag will be uploaded to S3 and registered with the MINID service.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset
|
DatasetSpec
|
Specification of the dataset to download, including version and materialization options. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
DatasetBag |
'DatasetBag'
|
Object containing: - path: Local filesystem path to downloaded dataset - rid: Dataset's Resource Identifier - minid: Dataset's Minimal Viable Identifier (if MINID enabled) |
Note
MINID support requires s3_bucket to be configured when creating the DerivaML instance. The catalog's use_minid setting controls whether MINIDs are created.
Examples:
Download with default options: >>> spec = DatasetSpec(rid="1-abc123") # doctest: +SKIP >>> bag = ml.download_dataset_bag(dataset=spec) # doctest: +SKIP >>> print(f"Downloaded to {bag.path}") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/dataset.py
429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 | |
download_dir
download_dir(
cached: bool = False,
) -> Path
Returns the appropriate download directory.
Provides the appropriate directory path for storing downloaded files, either in the cache or working directory.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
cached
|
bool
|
If True, returns the cache directory path. If False, returns the working directory path. |
False
|
Returns:
| Name | Type | Description |
|---|---|---|
Path |
Path
|
Directory path where downloaded files should be stored. |
Example
cache_dir = ml.download_dir(cached=True) # doctest: +SKIP work_dir = ml.download_dir(cached=False) # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 | |
estimate_bag_size
estimate_bag_size(
dataset: "DatasetSpec",
) -> dict[str, Any]
Estimate the size of a dataset bag before downloading.
Generates the same download specification used by download_dataset_bag, then runs COUNT and SUM(Length) queries against the snapshot catalog to preview what a download will contain and how large it will be.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset
|
'DatasetSpec'
|
Specification of the dataset to estimate, including version and optional exclude_tables. |
required |
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
dict with keys: - tables: dict mapping table name to {row_count, is_asset, asset_bytes} - total_rows: total row count across all tables - total_asset_bytes: total size of asset files in bytes - total_asset_size: human-readable size string (e.g., "1.2 GB") |
Source code in src/deriva_ml/core/mixins/dataset.py
471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 | |
estimate_denormalized_size
estimate_denormalized_size(
include_tables: list[str],
) -> dict[str, Any]
Return schema shape + catalog-wide size estimates for a denormalized table.
This is the catalog-wide analog of
:meth:Dataset.describe_denormalized. It asks "if I were to
denormalize these tables across the entire catalog (not scoped
to any specific dataset), what would the result look like and
how big would it be?" Useful for rough size estimation before
committing to a bag export.
The return shape is aligned with :meth:estimate_bag_size and
is NOT the same as the dataset-scoped 13-key plan dict from
:meth:Dataset.describe_denormalized
(docs/user-guide/denormalization.md §8.3.2). Do not confuse
the two.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
include_tables
|
list[str]
|
List of table names to include in the join. |
required |
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
dict with these keys: |
dict[str, Any]
|
|
dict[str, Any]
|
|
dict[str, Any]
|
|
dict[str, Any]
|
|
dict[str, Any]
|
|
dict[str, Any]
|
|
Example::
info = ml.estimate_denormalized_size(["Image", "Subject"])
print(f"{info['total_rows']} rows across "
f"{len(info['tables'])} tables, "
f"{info['total_asset_size']} of assets")
See Also
Dataset.describe_denormalized: Dataset-scoped planning dict. Denormalizer.describe: Full dataset-scoped plan with ambiguity reporting. estimate_bag_size: Bag-level size estimation.
Source code in src/deriva_ml/core/mixins/dataset.py
531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 | |
feature_record_class
feature_record_class(
table: str | Table,
feature_name: str,
) -> type[FeatureRecord]
Returns a dynamically generated Pydantic model class for creating feature records.
Each feature has a unique set of columns based on its definition (terms, assets, metadata). This method returns a Pydantic class with fields corresponding to those columns, providing:
- Type validation: Values are validated against expected types (str, int, float, Path)
- Required field checking: Non-nullable columns must be provided
- Default values: Feature_Name is pre-filled with the feature's name
Field types in the generated class:
- {TargetTable} (str): Required. RID of the target record (e.g., Image RID)
- Execution (str, optional): RID of the execution for provenance tracking
- Feature_Name (str): Pre-filled with the feature name
- Term columns (str): Accept vocabulary term names
- Asset columns (str | Path): Accept asset RIDs or file paths
- Value columns: Accept values matching the column type (int, float, str)
Use lookup_feature() to inspect the feature's structure and see what columns
are available.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
The table containing the feature, either as name or Table object. |
required |
feature_name
|
str
|
Name of the feature to create a record class for. |
required |
Returns:
| Type | Description |
|---|---|
type[FeatureRecord]
|
type[FeatureRecord]: A Pydantic model class for creating validated feature records.
The class name follows the pattern |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the feature doesn't exist or the table is invalid. |
Example
Get the dynamically generated class
DiagnosisFeature = ml.feature_record_class("Image", "Diagnosis") # doctest: +SKIP
Create a validated feature record
record = DiagnosisFeature( # doctest: +SKIP ... Image="1-ABC", # Target record RID ... Diagnosis_Type="Normal", # Vocabulary term ... confidence=0.95, # Metadata column ... Execution="2-XYZ" # Provenance ... )
Convert to dict for insertion
record.model_dump() # doctest: +SKIP {'Image': '1-ABC', 'Diagnosis_Type': 'Normal', 'confidence': 0.95, ...}
Source code in src/deriva_ml/core/mixins/feature.py
210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 | |
feature_values
feature_values(
table: Table | str,
feature_name: str,
selector: Callable[
[list[FeatureRecord]],
FeatureRecord | None,
]
| None = None,
materialize_limit: int
| None = None,
execution_rids: list[str]
| None = None,
) -> Iterable[FeatureRecord]
Yield feature values for a single feature, one record per target RID.
Returns an iterator of typed FeatureRecord instances. Each record is
wide in shape — target RID, all value columns (vocab terms, asset
references, metadata columns), and provenance columns (Execution,
RCT) — exposed as typed attributes.
When a selector is provided, records are grouped by target RID and
the selector collapses each group to a single survivor. Target RIDs
whose group's selector returns None are omitted. When no selector
is provided, every raw record is yielded — multiple records per target
RID are possible.
This method has identical signatures and semantics across DerivaML,
Dataset, and DatasetBag. The bag implementation reads from a
per-feature denormalization cache populated on first access; subsequent
calls are cheap.
All rows for the feature are fetched from the catalog before the first
record is yielded — this method is iterator-shaped for composability,
not for streaming of very large feature tables. When execution_rids
is set, the catalog query is filtered server-side to those execution
RIDs only -- this is the recommended way to keep the materialization
cost bounded for cross-execution comparisons.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
Table | str
|
Target table the feature is defined on (name or Table). |
required |
feature_name
|
str
|
Name of the feature to read. |
required |
selector
|
Callable[[list[FeatureRecord]], FeatureRecord | None] | None
|
Optional callable
|
None
|
materialize_limit
|
int | None
|
Optional cap on the number of rows that
may be materialized into memory. When the catalog query
returns more than this many rows, raises
|
None
|
execution_rids
|
list[str] | None
|
Optional filter -- when set, only feature
rows whose |
None
|
Returns:
| Type | Description |
|---|---|
Iterable[FeatureRecord]
|
Iterator of |
Iterable[FeatureRecord]
|
selector reduction, or all raw records if no selector. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableNotFound
|
|
DerivaMLException
|
|
DerivaMLMaterializeLimitExceeded
|
If the result set exceeds
|
Example
Get the newest Glaucoma label per image::
>>> from deriva_ml import DerivaML # doctest: +SKIP
>>> from deriva_ml.feature import FeatureRecord # doctest: +SKIP
>>> for rec in ml.feature_values( # doctest: +SKIP
... "Image", "Glaucoma", selector=FeatureRecord.select_newest,
... ):
... print(f"{rec.Image}: {rec.Glaucoma} (by {rec.Execution})")
Filter by a specific workflow — works identically on a downloaded bag.
select_by_workflow takes a str (Workflow_Type name or
Workflow RID); the underlying list_workflow_executions
call is @validate_call'd to str and will reject a
Workflow object outright::
>>> # By Workflow_Type name (the common case):
>>> sel = FeatureRecord.select_by_workflow( # doctest: +SKIP
... "Glaucoma_Training_v2", container=ml,
... )
>>> # ... or by Workflow RID, when you need a specific run:
>>> workflow = ml.lookup_workflow("Glaucoma_Training_v2") # doctest: +SKIP
>>> sel = FeatureRecord.select_by_workflow( # doctest: +SKIP
... workflow.workflow_rid, container=ml,
... )
>>> labels = [r.Glaucoma for r in ml.feature_values( # doctest: +SKIP
... "Image", "Glaucoma", selector=sel,
... )]
Convert to a pandas DataFrame when needed::
>>> import pandas as pd # doctest: +SKIP
>>> df = pd.DataFrame( # doctest: +SKIP
... r.model_dump()
... for r in ml.feature_values("Image", "Glaucoma")
... )
Source code in src/deriva_ml/core/mixins/feature.py
449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 | |
find_assets
find_assets(
asset_table: Table
| str
| None = None,
asset_type: str | None = None,
) -> Iterable["Asset"]
Find assets in the catalog.
Returns an iterable of Asset objects matching the specified criteria. If no criteria are specified, returns all assets from all asset tables.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_table
|
Table | str | None
|
Optional table or table name to search. If None, searches all asset tables. |
None
|
asset_type
|
str | None
|
Optional asset type to filter by. Only returns assets with this type. |
None
|
Returns:
| Type | Description |
|---|---|
Iterable['Asset']
|
Iterable of Asset objects matching the criteria. |
Example
Find all assets in the Model table
models = list(ml.find_assets(asset_table="Model")) # doctest: +SKIP
Find all assets with type "Training_Data"
training = list(ml.find_assets(asset_type="Training_Data")) # doctest: +SKIP
Find all assets across all tables
all_assets = list(ml.find_assets()) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 | |
find_datasets
find_datasets(
deleted: bool = False,
sort: SortSpec = None,
) -> Iterable["Dataset"]
List all datasets in the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
deleted
|
bool
|
If True, include datasets that have been marked as deleted. |
False
|
sort
|
SortSpec
|
Optional sort spec.
- |
None
|
Returns:
| Type | Description |
|---|---|
Iterable['Dataset']
|
Iterable of Dataset objects. |
Example
datasets = list(ml.find_datasets()) # doctest: +SKIP for ds in datasets: # doctest: +SKIP ... print(f"{ds.dataset_rid}: {ds.description}")
Newest-first (most common):
recent = list(ml.find_datasets(sort=True)) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/dataset.py
102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 | |
find_datasets_referencing
find_datasets_referencing(
table: str | Table,
column: str | None = None,
deleted: bool = False,
) -> list[DatasetReference]
Find the datasets impacted by a change to table (schema-evolution impact analysis).
Answers the catalog-evolver question "what breaks if I change
this table?": every dataset currently holding member rows of
table is reported, with its member count. Datasets reference
tables through their member associations (Dataset_<Table>),
so impact is table-granular -- membership is row-level, and
any column change on the member table affects every dataset
holding rows of that table. The column argument is accepted
for symmetry with :meth:find_features_referencing but does not
narrow the result; pair the two methods for a full impact
report.
Soft-deleted datasets are excluded by default, so this surface
agrees with :meth:find_datasets and :meth:lookup_dataset (both
default-exclude Deleted datasets). A soft delete keeps the
membership junction rows, so an association-only query would otherwise
report datasets that lookup_dataset then refuses (issue #355). Pass
deleted=True to include tombstoned datasets.
One bulk query for the members, plus one bulk query for the datasets'
Deleted status (skipped when deleted=True).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Name of the table (str) or |
required |
column
|
str | None
|
Optional column name, accepted for API symmetry. Dataset impact is table-granular, so this does not narrow the result. |
None
|
deleted
|
bool
|
If True, include soft-deleted datasets. Defaults to False
(soft-deleted datasets are excluded), matching
:meth: |
False
|
Returns:
| Name | Type | Description |
|---|---|---|
One |
list[DatasetReference]
|
class: |
list[DatasetReference]
|
|
|
list[DatasetReference]
|
|
|
list[DatasetReference]
|
the table is not a dataset element type anywhere. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableNotFound
|
If |
Example
refs = ml.find_datasets_referencing("Image") # doctest: +SKIP [(r.dataset_rid, r.member_count) for r in refs] # doctest: +SKIP [('1-AAAA', 550), ('1-BBBB', 110)]
Source code in src/deriva_ml/core/mixins/dataset.py
270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 | |
find_executions_consuming
find_executions_consuming(
rid: RID,
) -> list["ExecutionRecord"]
Forward lineage: the executions that CONSUMED the given artifact.
The forward complement of :meth:lookup_lineage (which walks
backward from an artifact to its producers). Given a Dataset or
asset RID, returns the executions that took it as an INPUT --
the "is it safe to delete this?" question: an empty result
means nothing recorded ever consumed it.
Dispatch is by resolved RID kind:
- Dataset -- executions with an input
Dataset_Executionedge to it (same edge :meth:find_executionsuses fordataset_role="input"). - Asset (any asset-table row) -- executions linked through
the asset's
<Asset>_Executionassociation withAsset_Role="Input".
Other RID kinds are not consumption-shaped and raise.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
rid
|
RID
|
RID of a Dataset or an asset-table row. |
required |
Returns:
| Type | Description |
|---|---|
list['ExecutionRecord']
|
List of :class: |
list['ExecutionRecord']
|
executions (empty when nothing consumed the artifact -- |
list['ExecutionRecord']
|
note this means "no RECORDED consumption"; producers are |
list['ExecutionRecord']
|
not consumers and are excluded). |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If |
Example
consumers = ml.find_executions_consuming("1-DS01") # doctest: +SKIP [e.execution_rid for e in consumers] # doctest: +SKIP ['2-EXE9'] ml.find_executions_consuming("1-LEAF") # doctest: +SKIP []
Source code in src/deriva_ml/core/mixins/execution.py
817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 | |
find_experiments
find_experiments(
workflow_rid: RID | None = None,
status: ExecutionStatus
| None = None,
) -> Iterable["Experiment"]
List all experiments (executions with Hydra configuration) in the catalog.
Creates Experiment objects for analyzing completed ML model runs. Only returns executions that have Hydra configuration metadata (i.e., a config.yaml file in Execution_Metadata assets).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
workflow_rid
|
RID | None
|
Optional workflow RID to filter by. |
None
|
status
|
ExecutionStatus | None
|
Optional status to filter by (e.g., ExecutionStatus.Uploaded). |
None
|
Returns:
| Type | Description |
|---|---|
Iterable['Experiment']
|
Iterable of Experiment objects for executions with Hydra config. |
Example
experiments = list(ml.find_experiments(status=ExecutionStatus.Uploaded)) # doctest: +SKIP for exp in experiments: # doctest: +SKIP ... print(f"{exp.name}: {exp.config_choices}")
Source code in src/deriva_ml/core/mixins/execution.py
944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 | |
find_features
find_features(
table: str | Table | None = None,
) -> list[Feature]
Find feature definitions in the schema.
Discovers features by inspecting the catalog schema for association tables
that have Feature_Name and Execution columns. Returns Feature objects
describing each feature's structure (target table, term/asset/value columns),
not the feature values themselves.
Use feature_values to retrieve actual feature values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table | None
|
Optional table to find features for. If None, returns all feature definitions across all tables. |
None
|
Returns:
| Type | Description |
|---|---|
list[Feature]
|
A list of Feature instances describing the feature definitions. |
Examples:
Find all feature definitions: >>> all_features = ml.find_features() # doctest: +SKIP >>> for f in all_features: # doctest: +SKIP ... print(f"{f.target_table.name}.{f.feature_name}")
Find features defined on a specific table: >>> image_features = ml.find_features("Image") # doctest: +SKIP >>> print([f.feature_name for f in image_features]) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/feature.py
340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 | |
find_features_referencing
find_features_referencing(
table: str | Table,
column: str | None = None,
) -> list[FeatureReference]
Find the features impacted by a change to table (schema-evolution impact analysis).
Answers the catalog-evolver question "what breaks if I change
this table / column?" for the feature layer: a feature's
association table carries FKs to its target table (the
self-FK), to vocabulary tables (term columns), and to asset
tables (asset columns). Any feature whose association-table FK
lands on table (and, when column is given, on that
referenced column) is reported with the FK column names doing
the referencing.
Note that FKs reference key columns -- almost always RID --
so column= narrows by the referenced column name. Pair
with :meth:find_datasets_referencing for a full impact
report.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Name of the table (str) or |
required |
column
|
str | None
|
Optional referenced-column filter; only FKs whose referenced columns include this name count. |
None
|
Returns:
| Name | Type | Description |
|---|---|---|
One |
list[FeatureReference]
|
class: |
list[FeatureReference]
|
( |
|
list[FeatureReference]
|
|
|
list[FeatureReference]
|
feature_name). Empty list when nothing references the |
|
list[FeatureReference]
|
table. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableNotFound
|
If |
Example
refs = ml.find_features_referencing("Image") # doctest: +SKIP [r.feature_name for r in refs] # doctest: +SKIP ['BoundingBox', 'Quality']
Source code in src/deriva_ml/core/mixins/feature.py
369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 | |
find_incomplete_executions
find_incomplete_executions() -> (
list[ExecutionSnapshot]
)
Sugar over :meth:list_executions for everything not terminally done.
Reads from the workspace SQLite registry — no server contact. Returns executions in status in (Created, Running, Stopped, Failed, Pending_Upload) — the set of things a user would want to either resume, retry, or clean up. Excludes Uploaded (terminal success) and Aborted (terminal cleanup).
For live catalog queries returning mutable
:class:~deriva_ml.execution.execution_record.ExecutionRecord
objects, see find_executions(status=...).
Returns:
| Type | Description |
|---|---|
list[ExecutionSnapshot]
|
List of |
list[ExecutionSnapshot]
|
execution known to the local registry. |
Example
for snap in ml.find_incomplete_executions(): # doctest: +SKIP ... print(snap.rid, snap.status, snap.pending_rows)
Source code in src/deriva_ml/core/mixins/execution.py
469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 | |
find_workflows
find_workflows(
sort: SortSpec = None,
) -> list[Workflow]
Find all workflows in the catalog.
Catalog-level operation to find all workflow definitions, including their names, URLs, types, versions, and descriptions. Each returned Workflow is bound to the catalog, allowing its description to be updated.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
sort
|
SortSpec
|
Optional sort spec.
- |
None
|
Returns:
| Type | Description |
|---|---|
list[Workflow]
|
list[Workflow]: List of workflow objects, each containing: - name: Workflow name - url: Source code URL - workflow_type: Type(s) of workflow - version: Version identifier - description: Workflow description - workflow_rid: Resource identifier - checksum: Source code checksum |
Examples:
List all workflows and their descriptions::
>>> workflows = ml.find_workflows() # doctest: +SKIP
>>> for w in workflows: # doctest: +SKIP
... print(f"{w.name} (v{w.version}): {w.description}")
... print(f" Source: {w.url}")
Update a workflow's description (workflows are catalog-bound)::
>>> workflows = ml.find_workflows() # doctest: +SKIP
>>> workflows[0].description = "Updated description" # doctest: +SKIP
Newest-first (most common)::
>>> recent = list(ml.find_workflows(sort=True)) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/workflow.py
84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 | |
from_context
classmethod
from_context(
path: Path | str | None = None,
) -> Self
Create a DerivaML instance from a .deriva-context.json file.
Searches for .deriva-context.json starting from path (default: cwd),
walking up parent directories. This enables scripts generated by Claude
to connect to the same catalog without hardcoding connection details.
The context file is written by the MCP server's connect_catalog tool
and contains hostname, catalog_id, and default_schema.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
path
|
Path | str | None
|
Starting directory to search for the context file. Defaults to the current working directory. |
None
|
Returns:
| Type | Description |
|---|---|
Self
|
A new DerivaML instance configured from the context file. |
Raises:
| Type | Description |
|---|---|
FileNotFoundError
|
If no .deriva-context.json is found. |
Example::
# In a script generated by Claude:
from deriva_ml import DerivaML
ml = DerivaML.from_context()
subjects = ml.cache_table("Subject")
Source code in src/deriva_ml/core/base.py
200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 | |
gc_executions
gc_executions(
*,
older_than: "timedelta | None" = None,
status: "ExecutionStatus | list[ExecutionStatus] | None" = None,
delete_working_dir: bool = False,
) -> int
Garbage-collect execution registry rows matching the filters.
By default only removes registry state (SQLite rows and their
pending_rows / directory_rules). Pass delete_working_dir=True to
also rm -rf the on-disk execution root under the workspace.
Does NOT touch the catalog. Executions uploaded to the catalog remain there regardless of local gc.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
older_than
|
'timedelta | None'
|
If set, only gc executions whose last_activity is older than this timedelta. |
None
|
status
|
'ExecutionStatus | list[ExecutionStatus] | None'
|
Filter by status (single or list); None = any status. Typical: pass ExecutionStatus.Uploaded to clean up after successful uploads. |
None
|
delete_working_dir
|
bool
|
If True, remove the per-execution working directory from disk. Defaults to False (registry-only). |
False
|
Returns:
| Type | Description |
|---|---|
int
|
The number of executions removed. |
Example
from datetime import timedelta # doctest: +SKIP from deriva_ml.execution.state_store import ExecutionStatus # doctest: +SKIP n = ml.gc_executions( # doctest: +SKIP ... status=ExecutionStatus.Uploaded, ... older_than=timedelta(days=30), ... delete_working_dir=True, ... ) print(f"cleaned {n} old executions") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 | |
get_cache_size
get_cache_size() -> dict[
str, int | float
]
Get the current size of the cache directory.
Returns:
| Type | Description |
|---|---|
dict[str, int | float]
|
dict with keys: - 'total_bytes': Total size in bytes - 'total_mb': Total size in megabytes - 'file_count': Number of files - 'dir_count': Number of directories |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP size = ml.get_cache_size() # doctest: +SKIP print(f"Cache size: {size['total_mb']:.1f} MB ({size['file_count']} files)") # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1698 1699 1700 1701 1702 1703 1704 1705 1706 1707 1708 1709 1710 1711 1712 1713 1714 1715 1716 1717 1718 1719 1720 1721 1722 1723 1724 1725 | |
get_column_annotations
get_column_annotations(
table: str | Table, column_name: str
) -> dict[str, Any]
Get all Chaise display-related annotations for a column.
Returns display and column-display annotations. Missing annotations
are None.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
column_name
|
str
|
Name of the column. |
required |
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
Dict with keys |
dict[str, Any]
|
|
dict[str, Any]
|
|
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If |
Example
anns = ml.get_column_annotations("Image", "Filename") # doctest: +SKIP anns["display"] # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 | |
get_handlebars_template_variables
get_handlebars_template_variables(
table: str | Table,
) -> dict[str, Any]
Get all available template variables for a table.
Returns the columns, foreign keys, and special variables that can be used in Handlebars templates (row_markdown_pattern, markdown_pattern, etc.) for the specified table.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name or Table object. |
required |
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
Dictionary with columns, foreign_keys, special_variables, and helper_examples. |
Example
vars = ml.get_handlebars_template_variables("Image") # doctest: +SKIP for col in vars["columns"]: # doctest: +SKIP ... print(f"{col['name']}: {col['template']}")
Source code in src/deriva_ml/core/mixins/annotation.py
905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 | |
get_storage_summary
get_storage_summary() -> dict[str, Any]
Get a summary of local storage usage.
Returns:
| Name | Type | Description |
|---|---|---|
dict[str, Any]
|
dict with keys: - 'working_dir': Path to working directory - 'cache_dir': Path to cache directory - 'cache_size_mb': Cache size in MB - 'cache_file_count': Number of files in cache - 'execution_dir_count': Number of execution directories - 'execution_size_mb': Total size of execution directories in MB - 'total_size_mb': Combined size in MB - 'bag_count': Number of cached dataset bags - 'bag_size_mb': Total size of cached bags in MB - 'asset_count': Number of cached input assets - 'asset_size_mb': Total size of cached assets in MB |
|
Note |
dict[str, Any]
|
|
dict[str, Any]
|
|
|
dict[str, Any]
|
additive with it; |
|
dict[str, Any]
|
|
|
dict[str, Any]
|
counts only files outside the |
|
dict[str, Any]
|
counts are not tracked in the index); it is a floor, not a |
|
dict[str, Any]
|
full tally. |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP summary = ml.get_storage_summary() # doctest: +SKIP print(f"Total storage: {summary['total_size_mb']:.1f} MB") # doctest: +SKIP print(f" Cache: {summary['cache_size_mb']:.1f} MB") # doctest: +SKIP print(f" Executions: {summary['execution_size_mb']:.1f} MB") # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1935 1936 1937 1938 1939 1940 1941 1942 1943 1944 1945 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022 2023 2024 2025 2026 2027 2028 | |
get_table_annotations
get_table_annotations(
table: str | Table,
) -> dict[str, Any]
Get all Chaise display-related annotations for a table.
Returns the current values of display, visible-columns,
visible-foreign-keys, and table-display annotations. Missing
annotations are represented as None in the returned dict.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
Returns:
| Type | Description |
|---|---|
dict[str, Any]
|
Dict with keys |
dict[str, Any]
|
|
dict[str, Any]
|
|
dict[str, Any]
|
(dict | None). |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
anns = ml.get_table_annotations("Image") # doctest: +SKIP anns["visible_columns"] # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 | |
get_table_as_dataframe
get_table_as_dataframe(
table: str,
) -> pd.DataFrame
Get table contents as a pandas DataFrame.
Retrieves all contents of a table from the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str
|
Name of the table to retrieve. |
required |
Returns:
| Type | Description |
|---|---|
DataFrame
|
DataFrame containing all table contents. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableNotFound
|
If the table does not exist in any schema. |
Example
df = ml.get_table_as_dataframe("Subject") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/path_builder.py
151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 | |
get_table_as_dict
get_table_as_dict(
table: str,
) -> Iterable[dict[str, Any]]
Get table contents as dictionaries.
Retrieves all contents of a table from the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str
|
Name of the table to retrieve. |
required |
Returns:
| Type | Description |
|---|---|
Iterable[dict[str, Any]]
|
Iterable yielding dictionaries for each row. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableNotFound
|
If the table does not exist in any schema. |
Example
rows = list(ml.get_table_as_dict("Subject")) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/path_builder.py
170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 | |
instantiate
classmethod
instantiate(
config: DerivaMLConfig,
) -> Self
Create a DerivaML instance from a configuration object.
This method is the preferred way to instantiate DerivaML when using hydra-zen for configuration management. It accepts a DerivaMLConfig (Pydantic model) and unpacks it to create the instance.
This pattern allows hydra-zen's instantiate() to work with DerivaML:
Example with hydra-zen
from hydra_zen import builds, instantiate # doctest: +SKIP from deriva_ml import DerivaML # doctest: +SKIP from deriva_ml.core.config import DerivaMLConfig # doctest: +SKIP
Create a structured config using hydra-zen
DerivaMLConf = builds(DerivaMLConfig, populate_full_signature=True) # doctest: +SKIP
Configure for your environment
conf = DerivaMLConf( # doctest: +SKIP ... hostname='deriva.example.org', ... catalog_id='42', ... domain_schemas={'my_domain'}, ... )
Instantiate the config to get a DerivaMLConfig object
config = instantiate(conf) # doctest: +SKIP
Create the DerivaML instance
ml = DerivaML.instantiate(config) # doctest: +SKIP
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
config
|
DerivaMLConfig
|
A DerivaMLConfig object containing all configuration parameters. |
required |
Returns:
| Type | Description |
|---|---|
Self
|
A new DerivaML instance configured according to the config object. |
Note
The DerivaMLConfig class integrates with Hydra's configuration system
and registers custom resolvers for computing working directories.
See deriva_ml.core.config for details on configuration options.
Source code in src/deriva_ml/core/base.py
156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 | |
is_authenticated
is_authenticated() -> bool
Whether there is a valid authenticated session for this catalog.
Thin boolean over :meth:whoami: True if the server returns a
client identity (GET /authn/session → 200), False if there is no
session (401/404). Makes one network call.
A True result is a safe bet that catalog operations will work (the
credential is accepted by the server). It means "I am logged in," not
"every privileged operation will pass ACLs" — see :meth:whoami for the
authentication-vs-authorization distinction.
Returns:
| Name | Type | Description |
|---|---|---|
bool |
bool
|
True if authenticated, False otherwise. |
Raises:
| Type | Description |
|---|---|
HTTPError
|
For non-auth HTTP errors (propagated
from :meth: |
Example
if not ml.is_authenticated(): # doctest: +SKIP ... raise SystemExit("Log in first: deriva-globus-auth-utils login --host ...")
Source code in src/deriva_ml/core/base.py
853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 | |
is_snapshot
is_snapshot() -> bool
Check whether this DerivaML instance is connected to a catalog snapshot.
Returns:
| Type | Description |
|---|---|
bool
|
True if the underlying catalog has a snapshot timestamp, False otherwise. |
Source code in src/deriva_ml/core/base.py
801 802 803 804 805 806 807 | |
is_strict_preallocated_rid
is_strict_preallocated_rid(
table: str | Table,
) -> bool
Return True if the asset table has the strict-preallocated-RID annotation set.
Checks for the tag:isrd.isi.edu,2026:strict-preallocated-rid
annotation. Returns True iff the annotation is present with
{"strict": true}.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Asset table name or Table object. |
required |
Returns:
| Type | Description |
|---|---|
bool
|
True if strict mode is set on this table, False otherwise. |
Source code in src/deriva_ml/core/mixins/annotation.py
416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 | |
list_asset_executions
list_asset_executions(
asset_rid: str,
asset_role: str | None = None,
) -> list["ExecutionRecord"]
List all executions associated with an asset.
Given an asset RID, returns a list of executions that created or used the asset, along with the role (Input/Output) in each execution.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_rid
|
str
|
The RID of the asset to look up. |
required |
asset_role
|
str | None
|
Optional filter for asset role ('Input' or 'Output'). If None, returns all associations. |
None
|
Returns:
| Type | Description |
|---|---|
list['ExecutionRecord']
|
list[ExecutionRecord]: List of ExecutionRecord objects for the executions associated with this asset. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the asset RID is not found or not an asset. |
Example
Find all executions that created this asset
executions = ml.list_asset_executions("1-abc123", asset_role="Output") # doctest: +SKIP for exe in executions: # doctest: +SKIP ... print(f"Created by execution {exe.execution_rid}") # doctest: +SKIP
Find all executions that used this asset as input
executions = ml.list_asset_executions("1-abc123", asset_role="Input") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 | |
list_asset_tables
list_asset_tables() -> list[Table]
List all asset tables in the catalog.
Returns:
| Type | Description |
|---|---|
list[Table]
|
List of Table objects that are asset tables. |
Example
for table in ml.list_asset_tables(): # doctest: +SKIP ... print(f"Asset table: {table.name}") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 | |
list_assets
list_assets(
asset_table: Table | str,
) -> list["Asset"]
Lists contents of an asset table.
Returns a list of Asset objects for the specified asset table. Asset
types are pre-fetched in a single query and joined client-side to
avoid an N+1 round-trip pattern: for an asset table with N rows, the
catalog is hit twice (once for the assets, once for the
Asset_Type association rows) regardless of N.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_table
|
Table | str
|
Table or name of the asset table to list assets for. |
required |
Returns:
| Type | Description |
|---|---|
list['Asset']
|
list[Asset]: List of Asset objects for the assets in the table. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the table is not an asset table or doesn't exist. |
Example
assets = ml.list_assets("Image") # doctest: +SKIP for asset in assets: # doctest: +SKIP ... print(f"{asset.asset_rid}: {asset.filename}") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 | |
list_cached_assets
list_cached_assets() -> (
"list[CachedAsset]"
)
List cached input assets (assets/{rid}_{md5} entries).
These are written by Execution.download_asset(use_cache=True)
/ AssetSpec(cache=True).
Returns:
| Type | Description |
|---|---|
'list[CachedAsset]'
|
List of :class: |
'list[CachedAsset]'
|
records (empty when no assets are cached). |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP for a in ml.list_cached_assets(): # doctest: +SKIP ... print(a.rid, a.size_bytes) # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1896 1897 1898 1899 1900 1901 1902 1903 1904 1905 1906 1907 1908 1909 1910 1911 1912 1913 | |
list_cached_bags
list_cached_bags() -> 'list[CachedBag]'
List every dataset bag in the local cache.
Answers "what bags are currently cached?" without needing to know any dataset RID up front. One record per (bag, dataset-anchor) pair, most-recently-built first.
Returns:
| Type | Description |
|---|---|
'list[CachedBag]'
|
List of :class: |
'list[CachedBag]'
|
(empty when nothing is cached). |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP for bag in ml.list_cached_bags(): # doctest: +SKIP ... print(bag.dataset_rid, bag.version, bag.status.value) # doctest: +SKIP
Source code in src/deriva_ml/core/base.py
1854 1855 1856 1857 1858 1859 1860 1861 1862 1863 1864 1865 1866 1867 1868 1869 1870 1871 1872 1873 | |
list_dataset_element_types
list_dataset_element_types() -> (
Iterable[Table]
)
List the table types that can be added as dataset members.
Thin wrapper over :meth:DerivaModel.list_dataset_element_types;
the model layer owns the filter logic.
Returns:
| Type | Description |
|---|---|
Iterable[Table]
|
Iterable of |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the catalog schema cannot be read. |
Example
types = ml.list_dataset_element_types() # doctest: +SKIP print([t.name for t in types]) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/dataset.py
252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 | |
list_execution_assets
list_execution_assets(
execution_rid: str,
asset_role: str | None = None,
) -> list["Asset"]
List the assets linked to an execution.
Enumerates every asset associated with execution_rid across all
{Asset}_Execution association tables, optionally filtered by role.
This is the DerivaML-instance analog of
:meth:Execution.list_assets — same scope, same optional asset_role
filter — for callers holding an execution RID rather than a live
:class:~deriva_ml.execution.execution.Execution object.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
execution_rid
|
str
|
RID of the execution whose assets to list. |
required |
asset_role
|
str | None
|
Optional filter — |
None
|
Returns:
| Type | Description |
|---|---|
list['Asset']
|
list[Asset]: Asset objects linked to the execution. Empty if none match. |
Example
inputs = ml.list_execution_assets(exe_rid, asset_role="Input") # doctest: +SKIP for a in inputs: # doctest: +SKIP ... print(a.asset_rid, a.filename)
Source code in src/deriva_ml/core/mixins/asset.py
256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 | |
list_execution_dirs
list_execution_dirs() -> list[
dict[str, Any]
]
List execution working directories.
Returns information about each execution directory in the working directory, useful for identifying orphaned or incomplete execution outputs.
Returns:
| Type | Description |
|---|---|
list[dict[str, Any]]
|
List of dicts, each containing: - 'execution_rid': The execution RID (directory name) - 'path': Full path to the directory - 'size_bytes': Total size in bytes - 'size_mb': Total size in megabytes - 'modified': Last modification time (datetime) - 'file_count': Number of files |
Example
ml = DerivaML('deriva.example.org', 'my_catalog') # doctest: +SKIP dirs = ml.list_execution_dirs() # doctest: +SKIP for d in dirs: # doctest: +SKIP ... print(f"{d['execution_rid']}: {d['size_mb']:.1f} MB")
Source code in src/deriva_ml/core/base.py
1727 1728 1729 1730 1731 1732 1733 1734 1735 1736 1737 1738 1739 1740 1741 1742 1743 1744 1745 1746 1747 1748 1749 1750 1751 1752 1753 1754 1755 1756 1757 1758 1759 1760 1761 1762 1763 1764 1765 1766 1767 1768 1769 1770 1771 1772 1773 1774 1775 1776 1777 1778 1779 | |
list_executions
list_executions(
*,
status: "ExecutionStatus | list[ExecutionStatus] | None" = None,
workflow_rid: str | None = None,
mode: "ConnectionMode | None" = None,
since: datetime | None = None,
) -> list[ExecutionSnapshot]
Enumerate locally-known executions from the SQLite registry.
Reads from the workspace SQLite registry — no server contact.
Works in both online and offline mode. Each returned
ExecutionSnapshot is a frozen Pydantic value object captured
at query time; it cannot mutate the catalog. Pending-row counts
are included in the same pass.
For live catalog queries that return mutable
:class:~deriva_ml.execution.execution_record.ExecutionRecord
objects bound to the catalog, see find_executions() and
lookup_execution().
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
status
|
'ExecutionStatus | list[ExecutionStatus] | None'
|
Single ExecutionStatus or list to filter; None = all. |
None
|
workflow_rid
|
str | None
|
Match only executions tagged with this Workflow RID; None = all. |
None
|
mode
|
'ConnectionMode | None'
|
ConnectionMode the execution was last active under; None = all. |
None
|
since
|
datetime | None
|
Return only executions with last_activity >= this timestamp (timezone-aware). None = no time filter. |
None
|
Returns:
| Type | Description |
|---|---|
list[ExecutionSnapshot]
|
List of |
list[ExecutionSnapshot]
|
row in the registry. Empty list if nothing matches. |
Example
from deriva_ml.execution.state_store import ExecutionStatus # doctest: +SKIP failed = ml.list_executions(status=ExecutionStatus.Failed) # doctest: +SKIP for snap in failed: # doctest: +SKIP ... print(snap.rid, snap.error)
Source code in src/deriva_ml/core/mixins/execution.py
396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 | |
list_files
list_files(
file_types: list[str] | None = None,
) -> list[dict[str, Any]]
Lists files in the catalog with their metadata.
Returns a list of files with their metadata including URL, MD5 hash, length, description, and associated file types. Files can be optionally filtered by type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
file_types
|
list[str] | None
|
Filter results to only include these file types. |
None
|
Returns:
| Type | Description |
|---|---|
list[dict[str, Any]]
|
list[dict[str, Any]]: List of file records, each containing: - RID: Resource identifier - URL: File location - MD5: File hash - Length: File size - Description: File description - File_Types: List of associated file types |
Examples:
List all files: >>> files = ml.list_files() # doctest: +SKIP >>> for f in files: # doctest: +SKIP ... print(f"{f['RID']}: {f['URL']}")
Filter by file type: >>> image_files = ml.list_files(["image", "png"]) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/file.py
476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 | |
list_vocabulary_terms
list_vocabulary_terms(
table: str | Table,
) -> list[VocabularyTerm]
Lists all terms in a vocabulary table.
Retrieves all terms, their descriptions, and synonyms from a controlled vocabulary table.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Vocabulary table to list terms from (name or Table object). |
required |
Returns:
| Type | Description |
|---|---|
list[VocabularyTerm]
|
list[VocabularyTerm]: List of vocabulary terms with their metadata. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If table doesn't exist or is not a vocabulary table. |
Examples:
>>> terms = ml.list_vocabulary_terms("tissue_types")
>>> for term in terms:
... print(f"{term.name}: {term.description}")
... if term.synonyms:
... print(f" Synonyms: {', '.join(term.synonyms)}")
Source code in src/deriva_ml/core/mixins/vocabulary.py
305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 | |
list_workflow_executions
list_workflow_executions(
workflow: str,
) -> list[str]
Return execution RIDs that ran the given workflow.
The workflow argument resolves in two steps: first as a Workflow
RID, and if that fails, as a Workflow_Type name. The returned list
contains every execution RID for every workflow that matches.
This method is the catalog-backed building block for
FeatureRecord.select_by_workflow(workflow, container=ml) — it
resolves the workflow's execution set once, and the selector closes
over the result for cheap per-group membership testing.
Entries are unique by construction (each execution runs one workflow).
Consumers that need O(1) membership testing convert to set at the
call site.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
workflow
|
str
|
Workflow RID (e.g., |
required |
Returns:
| Type | Description |
|---|---|
list[str]
|
List of execution RIDs, in insertion order. May be empty if the |
list[str]
|
workflow exists but has no executions yet. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If |
Example
List all executions of a workflow and count them::
>>> rids = ml.list_workflow_executions("Glaucoma_Training_v2") # doctest: +SKIP
>>> print(f"{len(rids)} executions of this workflow") # doctest: +SKIP
Use as the catalog-backed resolver for the selector factory::
>>> from deriva_ml.feature import FeatureRecord # doctest: +SKIP
>>> sel = FeatureRecord.select_by_workflow( # doctest: +SKIP
... "Glaucoma_Training_v2", container=ml,
... )
Source code in src/deriva_ml/core/mixins/feature.py
605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 | |
lookup_asset
lookup_asset(asset_rid: RID) -> 'Asset'
Look up an asset by its RID.
Returns an Asset object for the specified RID. The asset can be from any asset table in the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
asset_rid
|
RID
|
The RID of the asset to look up. |
required |
Returns:
| Type | Description |
|---|---|
'Asset'
|
Asset object for the specified RID. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the RID is not found or is not an asset. |
Example
asset = ml.lookup_asset("3JSE") # doctest: +SKIP print(f"File: {asset.filename}, Table: {asset.asset_table}") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/asset.py
340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 | |
lookup_dataset
lookup_dataset(
dataset: RID | DatasetSpec,
deleted: bool = False,
) -> "Dataset"
Look up a dataset by RID or DatasetSpec.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataset
|
RID | DatasetSpec
|
Dataset RID or DatasetSpec to look up. |
required |
deleted
|
bool
|
If True, include datasets that have been marked as deleted. |
False
|
Returns:
| Name | Type | Description |
|---|---|---|
Dataset |
'Dataset'
|
The dataset object for the specified RID. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the dataset is not found. |
Example
dataset = ml.lookup_dataset("4HM") # doctest: +SKIP print(f"Version: {dataset.current_version}") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/dataset.py
164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 | |
lookup_execution
lookup_execution(
execution_rid: RID,
) -> "ExecutionRecord"
Look up a single execution by RID in the live catalog.
Queries the ERMrest catalog for the Execution row with the given
RID and returns an ExecutionRecord — a live, catalog-bound
value whose mutable properties (status, description)
write through to the catalog on assignment. Online mode only.
For enumerating executions from the local SQLite registry without
touching the catalog, see list_executions(). For catalog-side
filter queries returning live records, see find_executions().
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
execution_rid
|
RID
|
Resource Identifier (RID) of the execution. |
required |
Returns:
| Type | Description |
|---|---|
'ExecutionRecord'
|
A live |
'ExecutionRecord'
|
setters ( |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If execution_rid is not valid or doesn't refer to an Execution record. |
Example
record = ml.lookup_execution("1-abc123") # doctest: +SKIP record.status = ExecutionStatus.Uploaded # writes to catalog # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 | |
lookup_experiment
lookup_experiment(
execution_rid: RID,
) -> "Experiment"
Look up an experiment by execution RID.
Creates an Experiment object for analyzing completed executions. Provides convenient access to execution metadata, configuration choices, model parameters, inputs, and outputs.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
execution_rid
|
RID
|
Resource Identifier (RID) of the execution. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
Experiment |
'Experiment'
|
An experiment object for the given execution RID. |
Example
exp = ml.lookup_experiment("47BE") # doctest: +SKIP print(exp.name) # e.g., "cifar10_quick" # doctest: +SKIP print(exp.config_choices) # Hydra config names used # doctest: +SKIP print(exp.model_config) # Model hyperparameters # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 | |
lookup_feature
lookup_feature(
table: str | Table,
feature_name: str,
) -> Feature
Look up a feature definition by table and name.
Returns a Feature object that describes the schema structure
of a feature — not the feature values themselves. A Feature is a
schema-level descriptor derived by inspecting the catalog's
association tables. It tells you:
- What table the feature annotates (
target_table) — e.g., Image - Where values are stored (
feature_table) — the association table linking targets to values and executions -
What kind of values it holds, classified by column role:
-
term_columns: columns referencing controlled vocabulary tables (e.g., aDiagnosis_Typecolumn pointing to a vocabulary of diagnosis terms) asset_columns: columns referencing asset tables (e.g., aSegmentation_Maskcolumn)value_columns: columns holding direct values like floats, ints, or text (e.g., aconfidencescore)
The Feature object also provides feature_record_class(), which
returns a dynamically generated Pydantic model for constructing
validated feature records to insert into the catalog.
To retrieve actual feature values, use feature_values
instead.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
The table the feature is defined on (name or Table object). |
required |
feature_name
|
str
|
Name of the feature to look up. |
required |
Returns:
| Type | Description |
|---|---|
Feature
|
A Feature schema descriptor. |
Raises:
| Type | Description |
|---|---|
DerivaMLFeatureNotFound
|
If the feature doesn't exist on the
specified table. Subclass of DerivaMLException — existing
|
Example
feature = ml.lookup_feature("Image", "Classification") # doctest: +SKIP print(f"Feature: {feature.feature_name}") # doctest: +SKIP print(f"Stored in: {feature.feature_table.name}") # doctest: +SKIP print(f"Term columns: {[c.name for c in feature.term_columns]}") # doctest: +SKIP print(f"Value columns: {[c.name for c in feature.value_columns]}") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/feature.py
291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 | |
lookup_lineage
lookup_lineage(
rid: RID,
*,
depth: int | None = None,
max_executions: int = 500,
) -> "LineageResult"
Walk the data-flow provenance chain behind an artifact.
Given a Dataset, Asset, Feature value, or Execution RID, returns a tree of producing executions and their consumed inputs back to the natural root of every branch. Replaces what would otherwise be 5-15 client round-trips through typed read methods with one call.
The walk follows data-flow parents only: for each
execution node, the parents are the producing executions of
its consumed datasets and assets (asset_role="Input"). This
method explicitly does NOT walk Execution_Execution
(orchestration links) — that's a different question
(ExecutionRecord.list_execution_parents /
list_execution_children). See
docs/adr/0001-lineage-walks-data-flow-not-orchestration.md
for the rationale.
For Dataset roots, the producer is taken from the current
version's Dataset_Version.Execution row. Walking a
historical version is a future enhancement.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
rid
|
RID
|
RID of any Dataset, Asset, Feature value, or
Execution. Workflow RIDs are not lineage-shaped and
raise :class: |
required |
depth
|
int | None
|
Number of parent levels to walk from the immediate
producing execution. |
None
|
max_executions
|
int
|
Defensive cap on distinct executions the
walk will expand. Default 500. If exceeded,
|
500
|
Returns:
| Name | Type | Description |
|---|---|---|
A |
'LineageResult'
|
class: |
'LineageResult'
|
with the producing-execution tree plus transparency |
|
'LineageResult'
|
flags ( |
|
'LineageResult'
|
|
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If |
Example
Trace an output asset back to its training dataset::
>>> result = ml.lookup_lineage("3JSE") # doctest: +SKIP
>>> assert result.walked_complete # doctest: +SKIP
>>> for ds in result.lineage.consumed_datasets: # doctest: +SKIP
... print(ds.rid, ds.version)
Just the immediate producer (one round-trip)::
>>> result = ml.lookup_lineage( # doctest: +SKIP
... "3JSE", depth=0,
... )
>>> producer = result.lineage.execution # doctest: +SKIP
For the orchestration view (which execution called
which), use record.list_execution_parents() /
list_execution_children() on an
:class:~deriva_ml.execution.execution_record.ExecutionRecord.
Source code in src/deriva_ml/core/mixins/execution.py
1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 | |
lookup_term
lookup_term(
table: str | Table, term_name: str
) -> VocabularyTermHandle
Finds a term in a vocabulary table.
Searches for a term in the specified vocabulary table, matching either the primary name or any of its synonyms. Results are cached for performance - subsequent lookups in the same vocabulary table are served from cache.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Vocabulary table to search in (name or Table object). |
required |
term_name
|
str
|
Name or synonym of the term to find. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
VocabularyTermHandle |
VocabularyTermHandle
|
The matching vocabulary term, with methods to modify it. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If the table is not a vocabulary table. |
DerivaMLInvalidTerm
|
If |
Examples:
Look up by primary name: >>> term = ml.lookup_term("tissue_types", "epithelial") # doctest: +SKIP >>> print(term.description) # doctest: +SKIP
Look up by synonym: >>> term = ml.lookup_term("tissue_types", "epithelium") # doctest: +SKIP
Modify the term: >>> term = ml.lookup_term("tissue_types", "epithelial") # doctest: +SKIP >>> term.description = "Updated description" # doctest: +SKIP >>> term.synonyms = ("epithelium", "epithelial_tissue") # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/vocabulary.py
201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 | |
lookup_workflow
lookup_workflow(rid: RID) -> Workflow
Look up a workflow by its Resource Identifier (RID).
Retrieves a workflow from the catalog by its RID and returns a Workflow object bound to the catalog. The returned Workflow can be modified (e.g., updating its description) and changes will be reflected in the catalog.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
rid
|
RID
|
Resource Identifier of the workflow to look up. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
Workflow |
Workflow
|
The workflow object bound to this catalog, allowing
properties like |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the RID does not correspond to a workflow in the catalog. |
Examples:
Look up a workflow and read its properties::
>>> workflow = ml.lookup_workflow("2-ABC1") # doctest: +SKIP
>>> print(f"Name: {workflow.name}") # doctest: +SKIP
>>> print(f"Description: {workflow.description}") # doctest: +SKIP
>>> print(f"Type: {workflow.workflow_type}") # doctest: +SKIP
Update a workflow's description (persisted to catalog)::
>>> workflow = ml.lookup_workflow("2-ABC1") # doctest: +SKIP
>>> workflow.description = "Updated analysis pipeline for RNA sequences" # doctest: +SKIP
>>> # The change is immediately written to the catalog
Attempting to update on a read-only catalog raises an error::
>>> snapshot = ml.catalog_snapshot("2023-01-15T10:30:00") # doctest: +SKIP
>>> workflow = snapshot.lookup_workflow("2-ABC1") # doctest: +SKIP
>>> workflow.description = "New description" # doctest: +SKIP
DerivaMLException: Cannot update workflow description on a read-only
catalog snapshot. Use a writable catalog connection instead.
Source code in src/deriva_ml/core/mixins/workflow.py
220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 | |
lookup_workflow_by_url
lookup_workflow_by_url(
url_or_checksum: str,
) -> Workflow
Look up a workflow by URL or checksum and return the full Workflow object.
Searches for a workflow in the catalog that matches the given URL or checksum and returns a Workflow object bound to the catalog. This allows you to both identify a workflow by its source code location and modify its properties (e.g., description).
The URL should be a GitHub URL pointing to the specific version of the workflow source code. The format typically includes the commit hash::
https://github.com/org/repo/blob/<commit_hash>/path/to/workflow.py
Alternatively, you can search by the Git object hash (checksum) of the workflow file.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
url_or_checksum
|
str
|
GitHub URL with commit hash, or Git object hash (checksum) of the workflow file. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
Workflow |
Workflow
|
The workflow object bound to this catalog, allowing
properties like |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If no workflow with the given URL or checksum is found in the catalog. |
Examples:
Look up a workflow by its GitHub URL::
>>> url = "https://github.com/org/repo/blob/abc123/analysis.py" # doctest: +SKIP
>>> workflow = ml.lookup_workflow_by_url(url) # doctest: +SKIP
>>> print(f"Found: {workflow.name}") # doctest: +SKIP
>>> print(f"Version: {workflow.version}") # doctest: +SKIP
Look up by Git object hash (checksum)::
>>> workflow = ml.lookup_workflow_by_url("abc123def456789...") # doctest: +SKIP
>>> print(f"Name: {workflow.name}") # doctest: +SKIP
>>> print(f"URL: {workflow.url}") # doctest: +SKIP
Update the workflow's description after lookup::
>>> workflow = ml.lookup_workflow_by_url(url) # doctest: +SKIP
>>> workflow.description = "Updated analysis pipeline" # doctest: +SKIP
>>> # The change is persisted to the catalog
Typical GitHub URL formats supported::
# Full blob URL with commit hash
https://github.com/org/repo/blob/abc123def/src/workflow.py
# The URL is matched exactly, so ensure it matches what was
# recorded when the workflow was registered
Source code in src/deriva_ml/core/mixins/workflow.py
307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 | |
multirun_status_summary
multirun_status_summary(
workflow_rid: RID,
) -> "MultirunStatusSummary"
Status counts across all executions of one workflow, in one query.
The "is the sweep done?" question: instead of listing every
execution record and counting client-side, fetch only the
Status column for the workflow's executions and aggregate.
Null Status values are counted under "Created",
matching :meth:lookup_execution's read contract
(Status or "Created").
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
workflow_rid
|
RID
|
RID of the workflow to summarize. |
required |
Returns:
| Type | Description |
|---|---|
'MultirunStatusSummary'
|
class: |
'MultirunStatusSummary'
|
|
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If |
Example
summary = ml.multirun_status_summary("1-WF01") # doctest: +SKIP summary.counts # doctest: +SKIP {'Uploaded': 18, 'Running': 2, 'Failed': 1} summary.total # doctest: +SKIP 21
Source code in src/deriva_ml/core/mixins/execution.py
872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 | |
pathBuilder
pathBuilder() -> (
"datapath._CatalogWrapper"
)
Returns catalog path builder for queries.
The path builder provides a fluent interface for constructing complex queries against the catalog. This is a core component used by many other methods to interact with the catalog.
Returns:
| Type | Description |
|---|---|
'datapath._CatalogWrapper'
|
datapath._CatalogWrapper: A new instance of the catalog path builder. |
Raises:
| Type | Description |
|---|---|
Exception
|
If the catalog connection is unavailable. |
Example
pb = ml.pathBuilder() # doctest: +SKIP path = pb.schemas['my_schema'].tables['my_table'] # doctest: +SKIP results = path.entities().fetch() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/path_builder.py
59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 | |
pending_summary
pending_summary() -> (
"WorkspacePendingSummary"
)
Workspace-wide pending-upload summary.
Queries every known-local execution and returns a WorkspacePendingSummary aggregating per-execution snapshots. Useful for standalone uploader processes that want to know what's pending across runs.
Returns:
| Type | Description |
|---|---|
'WorkspacePendingSummary'
|
WorkspacePendingSummary with one PendingSummary per execution |
'WorkspacePendingSummary'
|
that has at least one registry row. |
Example
print(ml.pending_summary().render()) # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 | |
pin_schema
pin_schema(
reason: str | None = None,
) -> "SchemaDiff | None"
Freeze the local schema cache at its current snapshot.
While pinned, :meth:refresh_schema refuses to update the
cache (even with force=True). Call :meth:unpin_schema
to clear the pin.
Online mode additionally checks for structural drift: if the
live catalog has moved on and its /schema payload differs
from the cached one (columns, tables, foreign keys, etc.),
a :class:SchemaDiff describing the drift is returned, and
a WARNING is logged. The pin is still persisted.
Offline mode always returns None — the cache is pinned,
but no live comparison is possible.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
reason
|
str | None
|
Free-text explanation stored alongside the pin.
Useful for reporting ( |
None
|
Returns:
| Name | Type | Description |
|---|---|---|
A |
'SchemaDiff | None'
|
class: |
'SchemaDiff | None'
|
the live catalog's schema differs structurally from the |
|
'SchemaDiff | None'
|
cache. |
|
'SchemaDiff | None'
|
bumped without schema change). |
Raises:
| Type | Description |
|---|---|
FileNotFoundError
|
If the workspace has no cache yet.
Run an online |
Source code in src/deriva_ml/core/base.py
655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 | |
pin_status
pin_status() -> 'PinStatus'
Return the current pin state of the local schema cache.
Works in any mode.
Returns:
| Name | Type | Description |
|---|---|---|
A |
'PinStatus'
|
class: |
'PinStatus'
|
|
|
'PinStatus'
|
|
|
'PinStatus'
|
|
Raises:
| Type | Description |
|---|---|
FileNotFoundError
|
If the workspace has no cache file. |
Source code in src/deriva_ml/core/base.py
719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 | |
refresh_schema
refresh_schema(
*, force: bool = False
) -> None
Force-refetch the live catalog schema; rebuild the model and disk cache.
Online mode only. For normal in-process use this method is
rarely needed: deriva-py's ErmrestCatalog already handles
schema freshness automatically (auto-invalidation on same-
instance mutations, If-None-Match revalidation on every
read). Use refresh_schema() when you specifically need to
bypass the in-process cache and re-fetch from the live
catalog -- e.g. after a known out-of-band mutation by another
process, or before overwriting the offline-mode disk cache.
The disk cache (SchemaCache) is rewritten with the fresh
/schema JSON so subsequent offline-mode reads see the new
snapshot. The in-memory self.model is rebuilt from the
same fresh JSON.
Refuses in two cases:
- The disk cache is pinned (via :meth:
pin_schema). Raises :class:DerivaMLSchemaPinned.force=Truedoes NOT bypass a pin — call :meth:unpin_schemafirst. - The workspace has pending rows (staged/leasing/leased/
uploading/failed). Raises
:class:
DerivaMLSchemaRefreshBlockedunlessforce=Trueis passed; a forced refresh may leave staged rows whose metadata references columns or types no longer in the new schema, causing catalog-insert failures on the next upload.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
force
|
bool
|
If True, refresh even when the workspace has pending rows. Does NOT bypass a pin. |
False
|
Raises:
| Type | Description |
|---|---|
DerivaMLOfflineError
|
If called in offline mode. |
DerivaMLSchemaPinned
|
If the disk cache is pinned (any
|
DerivaMLSchemaRefreshBlocked
|
If |
Source code in src/deriva_ml/core/base.py
562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 | |
remove_visible_column
remove_visible_column(
table: str | Table,
context: str,
column: str | list[str] | int,
) -> list[Any]
Remove a column from the visible-columns list for a specific context.
Convenience method for removing columns without replacing the entire
visible-columns annotation. Changes are staged until
apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
context
|
str
|
The context to modify (e.g., |
required |
column
|
str | list[str] | int
|
Column to remove. Can be:
- str: column name to find and remove
- list: foreign key reference |
required |
Returns:
| Type | Description |
|---|---|
list[Any]
|
The updated column list for the context. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If the annotation or context doesn't exist, or the column is not found. |
Example
ml.remove_visible_column("Image", "compact", "Description") # doctest: +SKIP ml.remove_visible_column("Image", "compact", 0) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 | |
remove_visible_foreign_key
remove_visible_foreign_key(
table: str | Table,
context: str,
foreign_key: list[str] | int,
) -> list[Any]
Remove a foreign key from the visible-foreign-keys list for a specific context.
Convenience method for removing related tables without replacing the
entire visible-foreign-keys annotation. Changes are staged until
apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
context
|
str
|
The context to modify (e.g., |
required |
foreign_key
|
list[str] | int
|
Foreign key to remove. Can be:
- list: FK reference |
required |
Returns:
| Type | Description |
|---|---|
list[Any]
|
The updated foreign key list for the context. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If the annotation or context doesn't exist, or the foreign key is not found. |
Example
ml.remove_visible_foreign_key("Subject", "detailed", ["domain", "Image_Subject_fkey"]) # doctest: +SKIP ml.remove_visible_foreign_key("Subject", "detailed", 0) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 | |
reorder_visible_columns
reorder_visible_columns(
table: str | Table,
context: str,
new_order: list[int]
| list[
str | list[str] | dict[str, Any]
],
) -> list[Any]
Reorder columns in the visible-columns list for a specific context.
Convenience method for reordering columns without manually
reconstructing the list. Changes are staged until
apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
context
|
str
|
The context to modify (e.g., |
required |
new_order
|
list[int] | list[str | list[str] | dict[str, Any]]
|
The new order specification. Can be:
- list of int: |
required |
Returns:
| Type | Description |
|---|---|
list[Any]
|
The reordered column list. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If the annotation or context doesn't exist, or the index list is invalid. |
Example
ml.reorder_visible_columns("Image", "compact", [2, 0, 1, 3, 4]) # doctest: +SKIP ml.reorder_visible_columns("Image", "compact", ["Filename", "Subject", "RID"]) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 | |
reorder_visible_foreign_keys
reorder_visible_foreign_keys(
table: str | Table,
context: str,
new_order: list[int]
| list[list[str] | dict[str, Any]],
) -> list[Any]
Reorder foreign keys in the visible-foreign-keys list for a specific context.
Convenience method for reordering related tables without manually
reconstructing the list. Changes are staged until
apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
context
|
str
|
The context to modify (e.g., |
required |
new_order
|
list[int] | list[list[str] | dict[str, Any]]
|
The new order specification. Can be:
- list of int: |
required |
Returns:
| Type | Description |
|---|---|
list[Any]
|
The reordered foreign key list. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
DerivaMLException
|
If the annotation or context doesn't exist, or the index list is invalid. |
Example
ml.reorder_visible_foreign_keys("Subject", "detailed", [2, 0, 1]) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 | |
resolve_rid
resolve_rid(
rid: RID,
) -> ResolveRidResult
Resolves RID to catalog location.
Looks up a RID and returns information about where it exists in the catalog, including schema, table, and column metadata.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
rid
|
RID
|
Resource Identifier to resolve. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
ResolveRidResult |
ResolveRidResult
|
Named tuple containing: - schema: Schema name - table: Table name - columns: Column definitions - datapath: Path builder for accessing the entity |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If RID doesn't exist in catalog. |
Examples:
>>> result = ml.resolve_rid("1-abc123")
>>> print(f"Found in {result.schema}.{result.table}")
>>> data = result.datapath.entities().fetch()
Source code in src/deriva_ml/core/mixins/rid_resolution.py
96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 | |
resolve_rids
resolve_rids(
rids: set[RID] | list[RID],
candidate_tables: list[Table]
| None = None,
) -> dict[RID, BatchRidResult]
Batch resolve multiple RIDs efficiently.
Resolves multiple RIDs in batched queries, far faster than calling
resolve_rid once per RID. RIDs are matched against a table with a
single chunked RID = Any(...) query rather than N per-RID lookups.
Two strategies depending on candidate_tables:
- Explicit candidate tables (e.g. dataset element types): each listed table is bulk-matched in turn until every RID is resolved.
- No candidate tables (
None): instead of scanning every table in the domain + ML schemas (a wasted zero-row query per table that holds none of the RIDs), the server is asked which table a sample RID lives in viaresolve_rid(one/entity_ridcall, catalog-wide), the rest are bulk-matched in that table, and the process repeats for any RIDs in other tables. Cost is ~one probe per distinct table the RIDs actually span, independent of catalog size.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
rids
|
set[RID] | list[RID]
|
Set or list of RIDs to resolve. |
required |
candidate_tables
|
list[Table] | None
|
Optional list of Table objects to search in. If not provided, the server resolves each RID's table directly (probe strategy above) — note this resolves catalog-wide, so a RID in any schema is found, not only domain/ML schemas. |
None
|
Returns:
| Type | Description |
|---|---|
dict[RID, BatchRidResult]
|
dict[RID, BatchRidResult]: Mapping from each resolved RID to its BatchRidResult containing table information. |
Raises:
| Type | Description |
|---|---|
DerivaMLRidsNotFound
|
If any RID cannot be resolved; the unresolved
set is available as |
Example
results = ml.resolve_rids(["1-ABC", "2-DEF", "3-GHI"]) # doctest: +SKIP for rid, info in results.items(): # doctest: +SKIP ... print(f"{rid} is in table {info.table_name}")
Source code in src/deriva_ml/core/mixins/rid_resolution.py
147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 | |
resume_execution
resume_execution(
execution_rid: RID,
) -> "Execution"
Re-hydrate an Execution from the workspace SQLite registry.
Works in both online and offline modes. The execution's recorded mode is independent of the current DerivaML instance's mode — a user can create an execution online, run it offline, then upload online, all via the same RID.
Before returning, runs just-in-time state reconciliation (spec §2.2): if online and sync_pending=True, flushes SQLite to the catalog; then checks for catalog/SQLite disagreement and applies the disagreement rules.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
execution_rid
|
RID
|
Server-assigned Execution RID returned by a prior create_execution call. |
required |
Returns:
| Type | Description |
|---|---|
'Execution'
|
An Execution object bound to this DerivaML instance, with |
'Execution'
|
lifecycle fields as SQLite read-through properties (see |
'Execution'
|
spec §2.3). |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If no matching executions row exists in the workspace registry. |
DerivaMLStateInconsistency
|
If just-in-time reconciliation surfaces a disagreement outside the six documented cases (see state_machine.reconcile_with_catalog). |
Example
ml = DerivaML(hostname="example.org", catalog_id="42") # doctest: +SKIP exe = ml.resume_execution("5-ABC") # doctest: +SKIP exe.status # doctest: +SKIP
exe.commit_output_assets() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 | |
set_column_display
set_column_display(
table: str | Table,
column_name: str,
annotation: dict[str, Any] | None,
) -> str
Set the column-display annotation on a column.
Controls how a column's values are rendered, including custom
formatting and markdown patterns. The annotation dict follows the
Chaise column-display tag specification, keyed by context name
(or "*" for all contexts), e.g.
{"*": {"pre_format": {"format": "%.2f"}}}.
Changes are staged locally until apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
column_name
|
str
|
Name of the column. |
required |
annotation
|
dict[str, Any] | None
|
The column-display annotation dict. Set to |
required |
Returns:
| Type | Description |
|---|---|
str
|
Column identifier as |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
ml.set_column_display("Measurement", "Value", { # doctest: +SKIP ... "*": {"pre_format": {"format": "%.2f"}} ... }) ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 | |
set_display_annotation
set_display_annotation(
table: str | Table,
annotation: dict[str, Any] | None,
column_name: str | None = None,
) -> str
Set the Chaise display annotation on a table or column.
The display annotation controls how the table or column is labeled in
the Chaise web UI. The dict shape follows the Chaise display tag
specification, e.g. {"name": "Human Readable Name"}.
Changes are staged locally until apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
annotation
|
dict[str, Any] | None
|
Annotation dict, e.g. |
required |
column_name
|
str | None
|
If provided, sets the annotation on that column; otherwise sets it on the table. |
None
|
Returns:
| Type | Description |
|---|---|
str
|
Target identifier — table name (str) when setting on the table, |
str
|
or |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
ml.set_display_annotation("Image", {"name": "Scan Image"}) # doctest: +SKIP ml.set_display_annotation("Image", {"name": "File Name"}, column_name="Filename") # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 | |
set_strict_preallocated_rid
set_strict_preallocated_rid(
table: str | Table,
strict: bool = True,
) -> str
Mark or unmark an asset table as strict-preallocated-RID.
When strict=True, deriva-py's uploader raises
DerivaUploadCatalogCreateError if an upload's caller-supplied
pre-allocated RID differs from an existing catalog row's RID for
the same MD5+Filename. When False (or the annotation is
absent), the uploader silently adopts the existing row's RID
(legacy behavior preserved for shared artifacts like
Execution_Metadata configs).
Use strict mode for tables whose rows are referenced by FK columns in the same upload batch — any unexpected RID reassignment would corrupt those references.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Asset table name or Table object. |
required |
strict
|
bool
|
If True, set the annotation to |
True
|
Returns:
| Type | Description |
|---|---|
str
|
The table's name. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
ml.set_strict_preallocated_rid("ScanResult", strict=True) # doctest: +SKIP ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 | |
set_table_display
set_table_display(
table: str | Table,
annotation: dict[str, Any] | None,
) -> str
Set the table-display annotation on a table.
Controls table-level display options such as row-naming patterns,
default page size, and sort order. The annotation dict follows the
Chaise table-display tag specification, e.g.
{"row_name": {"row_markdown_pattern": "{{{Name}}}"}}.
Changes are staged locally until apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
annotation
|
dict[str, Any] | None
|
The table-display annotation dict. Set to |
required |
Returns:
| Type | Description |
|---|---|
str
|
Table name. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
ml.set_table_display("Subject", { # doctest: +SKIP ... "row_name": { ... "row_markdown_pattern": "{{{Name}}} ({{{Species}}})" ... } ... }) ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 | |
set_visible_columns
set_visible_columns(
table: str | Table,
annotation: dict[str, Any] | None,
) -> str
Set the visible-columns annotation on a table.
Controls which columns appear in different UI contexts and their order.
The annotation is a dict mapping context names (e.g. "compact",
"detailed", "entry") to lists of column specs. Each spec may
be a plain column-name string, a foreign-key reference list
[schema, constraint_name], or a pseudo-column dict per the Chaise
visible-columns specification.
Changes are staged locally until apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
annotation
|
dict[str, Any] | None
|
The visible-columns annotation dict. Set to |
required |
Returns:
| Type | Description |
|---|---|
str
|
Table name. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
ml.set_visible_columns("Image", { # doctest: +SKIP ... "compact": ["RID", "Filename", "Subject"], ... "detailed": ["RID", "Filename", "Subject", "Description"] ... }) ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 | |
set_visible_foreign_keys
set_visible_foreign_keys(
table: str | Table,
annotation: dict[str, Any] | None,
) -> str
Set the visible-foreign-keys annotation on a table.
Controls which related tables (via inbound foreign keys) appear in
different UI contexts and their order. The annotation is a dict
mapping context names to lists of FK specs. Each FK spec is a list
[schema, constraint_name] referencing an inbound foreign key, or
a pseudo-column dict per the Chaise visible-foreign-keys specification.
Changes are staged locally until apply_annotations() is called.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table
|
str | Table
|
Table name (str) or |
required |
annotation
|
dict[str, Any] | None
|
The visible-foreign-keys annotation dict. Set to
|
required |
Returns:
| Type | Description |
|---|---|
str
|
Table name. |
Raises:
| Type | Description |
|---|---|
DerivaMLTableTypeError
|
If |
Example
ml.set_visible_foreign_keys("Subject", { # doctest: +SKIP ... "detailed": [ ... ["domain", "Image_Subject_fkey"], ... ["domain", "Diagnosis_Subject_fkey"] ... ] ... }) ml.apply_annotations() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/annotation.py
242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 | |
unknown_provenance_execution_rid
unknown_provenance_execution_rid() -> (
RID
)
RID of the seeded unknown-provenance Execution sentinel.
A producerless artifact attributes to this execution so lineage from
it reports "unknown origin" rather than dead-ending on a null
producer. Seeded by initialize_ml_schema.
Returns:
| Type | Description |
|---|---|
RID
|
The sentinel Execution's RID. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the sentinel is not present (catalog not initialized by a contract-aware deriva-ml). |
Example
rid = ml.unknown_provenance_execution_rid() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 | |
unknown_provenance_file_rid
unknown_provenance_file_rid() -> RID
RID of the seeded unknown-provenance File sentinel.
Linked as an Input to an artifact-producer that committed with no
declared input (the no-input commit check), so the gap is recorded as
an explicit "unknown input" edge rather than absent. Seeded by
initialize_ml_schema.
Returns:
| Type | Description |
|---|---|
RID
|
The sentinel File's RID. |
Raises:
| Type | Description |
|---|---|
DerivaMLException
|
If the sentinel is not present. |
Example
rid = ml.unknown_provenance_file_rid() # doctest: +SKIP
Source code in src/deriva_ml/core/mixins/execution.py
104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 | |
unpin_schema
unpin_schema() -> None
Clear the schema-cache pin. No-op if not pinned.
Works in any mode. After unpinning, :meth:refresh_schema
is allowed again (subject to the pending-rows guard).
Raises:
| Type | Description |
|---|---|
FileNotFoundError
|
If the workspace has no cache file. |
Source code in src/deriva_ml/core/base.py
708 709 710 711 712 713 714 715 716 717 | |
user_list
user_list() -> list[dict[str, str]]
Returns the catalog user list.
Retrieves basic information about all users who have access to the
catalog, from the public.ERMrest_Client table.
Note
The user table lives in the public schema, which is outside
the domain/ML schema search path used by
:meth:get_table_as_dict (name_to_table searches
domain_schemas → ml_schema → WWW). This method is the
supported accessor for catalog users; get_table_as_dict
cannot reach ERMrest_Client.
Returns:
| Type | Description |
|---|---|
list[dict[str, str]]
|
A list of user dictionaries, each with:
- |
Example
users = ml.user_list() # doctest: +SKIP for user in users: # doctest: +SKIP ... print(f"{user['Full_Name']} ({user['ID']})")
Source code in src/deriva_ml/core/mixins/path_builder.py
191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 | |
validate_config_directory
validate_config_directory(
configs_dir: str | PathLike[str],
*,
recursive: bool = True,
) -> ConfigValidationReport
Validate every *.py config file under configs_dir.
Walks the directory, parses each Python file, validates every
constructor call against the catalog, and aggregates the per-
file reports into one :class:ConfigValidationReport. A
single broken file does not abort the walk -- the error is
recorded in parse_errors and the validator continues with
the next file.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
configs_dir
|
str | PathLike[str]
|
Path to the configs directory (typically
|
required |
recursive
|
bool
|
When |
True
|
Returns:
| Name | Type | Description |
|---|---|---|
A |
ConfigValidationReport
|
class: |
ConfigValidationReport
|
all files, ordered first by file path then by line. |
Example
Validate the whole tree::
>>> report = ml.validate_config_directory( # doctest: +SKIP
... "src/configs"
... )
>>> if not report.all_valid: # doctest: +SKIP
... for r in report.results:
... if not r.valid:
... print(r.entry.file, r.entry.line, r.reasons)
... for pe in report.parse_errors:
... print("UNPARSEABLE:", pe.file, pe.message)
Source code in src/deriva_ml/core/mixins/dataset.py
907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 | |
validate_config_file
validate_config_file(
path: str | PathLike[str],
) -> ConfigValidationReport
Validate every spec constructor in one hydra-zen config file.
Parses the file via AST (no execution) and validates each
DatasetSpecConfig / AssetSpecConfig / Workflow /
DerivaMLConfig constructor call against the catalog.
Composes the existing :meth:validate_dataset_specs,
:meth:_validate_asset_spec, :meth:_validate_workflow_rid
primitives. For DerivaMLConfig entries the validator
compares the entry's hostname and catalog_id against
the catalog this :class:DerivaML instance is connected to;
a mismatch is reported but doesn't make catalog calls.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
path
|
str | PathLike[str]
|
Path to the file. Accepts |
required |
Returns:
| Name | Type | Description |
|---|---|---|
A |
ConfigValidationReport
|
class: |
ConfigValidationReport
|
class: |
|
ConfigValidationReport
|
(in source order). Files that fail to parse produce a |
|
single |
ConfigValidationReport
|
class: |
ConfigValidationReport
|
empty in that case. |
Does not raise on syntax errors or missing files -- both are reported structurally so a caller validating many files can record them without aborting the walk.
Example
Validate one file::
>>> report = ml.validate_config_file( # doctest: +SKIP
... "src/configs/datasets.py"
... )
>>> for r in report.results: # doctest: +SKIP
... if not r.valid:
... print(r.entry.file, r.entry.line, r.reasons)
Source code in src/deriva_ml/core/mixins/dataset.py
854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 | |
validate_dataset_specs
validate_dataset_specs(
specs: list[
DatasetSpec
| str
| dict[str, Any]
],
) -> DatasetSpecValidationReport
Validate a list of :class:DatasetSpec against the catalog.
Replaces the per-RID ml.lookup_dataset(rid) +
ds.dataset_history() cross-check loop a user would
otherwise write while iterating on src/configs/datasets.py.
Each spec is checked for three orthogonal failure modes —
rid_not_found, not_a_dataset, version_not_found —
and all three are reported per spec rather than stopping at
the first.
This is a metadata-only catalog query. For the heavier
full-path check (which materializes bags) see
:meth:Execution.dry_run. ADR-0002 captures the rationale
for keeping the two surfaces distinct.
Input shorthands are accepted for ergonomics: a plain RID
string is parsed via :meth:DatasetSpec.from_shorthand (so
"1-XYZ@1.0.0" and "1-XYZ" both work), and a dict is
coerced via DatasetSpec(**d).
Duplicate specs in the input are validated independently
(no deduplication). Cross-spec duplicate detection lives on
the composite :meth:validate_execution_configuration.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
specs
|
list[DatasetSpec | str | dict[str, Any]]
|
List of dataset specifications to validate. Each
element may be a :class: |
required |
Returns:
| Name | Type | Description |
|---|---|---|
A |
DatasetSpecValidationReport
|
class: |
DatasetSpecValidationReport
|
class: |
|
DatasetSpecValidationReport
|
order) plus a top-level |
Raises:
| Type | Description |
|---|---|
ValidationError
|
If any input element cannot be
coerced to a :class: |
Example
Validate two specs, one good and one with a typo'd version::
>>> from deriva_ml.dataset.aux_classes import DatasetReference, DatasetSpec # doctest: +SKIP
>>> report = ml.validate_dataset_specs(specs=[ # doctest: +SKIP
... DatasetSpec(rid="2-B4C8", version="0.4.0"),
... DatasetSpec(rid="2-B4C8", version="9.9.9"),
... ])
>>> report.all_valid # doctest: +SKIP
False
>>> bad = report.results[1] # doctest: +SKIP
>>> bad.reasons # doctest: +SKIP
['version_not_found']
>>> bad.available_versions # doctest: +SKIP
['0.4.0', '0.3.0']
Source code in src/deriva_ml/core/mixins/dataset.py
689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 | |
validate_execution_configuration
validate_execution_configuration(
config: "ExecutionConfiguration",
) -> ExecutionConfigurationValidationReport
Pre-flight validation for an :class:ExecutionConfiguration.
Walks the contained datasets and assets lists, validates
the workflow RID, and reports per-spec results plus cross-spec
issues (duplicate RIDs across the dataset list, dataset-version
conflicts, asset role conflicts). Designed to be cheap to run
repeatedly while iterating on a config — only catalog metadata
is touched, no bags are materialized.
This method is the lightweight complement to
:meth:Execution.dry_run. dry_run is the heavier full-path
test that exercises the bag-download + materialization pipeline;
validate_execution_configuration answers the cheaper
upstream question of "do the RIDs in this config refer to
things that exist in the catalog the way I think they do?".
See ADR-0002 for the full rationale.
The dataset half of the work is delegated to
:meth:validate_dataset_specs — the two methods share the
per-spec dataset validation logic.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
config
|
'ExecutionConfiguration'
|
The execution configuration to validate. Its
|
required |
Returns:
| Name | Type | Description |
|---|---|---|
A |
ExecutionConfigurationValidationReport
|
class: |
ExecutionConfigurationValidationReport
|
per-spec results, an optional workflow result (None if |
|
ExecutionConfigurationValidationReport
|
the config has no workflow set), cross-spec issues, and |
|
ExecutionConfigurationValidationReport
|
an |
Raises:
| Type | Description |
|---|---|
ValidationError
|
If |
Example
Validate a config before invoking deriva-ml-run::
>>> from deriva_ml.execution import ExecutionConfiguration # doctest: +SKIP
>>> from deriva_ml.dataset.aux_classes import DatasetReference, DatasetSpec # doctest: +SKIP
>>> from deriva_ml.asset.aux_classes import AssetSpec # doctest: +SKIP
>>> config = ExecutionConfiguration( # doctest: +SKIP
... workflow=workflow,
... datasets=[DatasetSpec(rid="2-B4C8", version="0.4.0")],
... assets=[AssetSpec(rid="3JSE")],
... )
>>> report = ml.validate_execution_configuration(config) # doctest: +SKIP
>>> if not report.all_valid: # doctest: +SKIP
... for issue in report.cross_spec_issues:
... print(issue.detail)
Source code in src/deriva_ml/core/mixins/dataset.py
763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 | |
whoami
whoami() -> dict | None
Return the authenticated client identity, or None if not logged in.
Asks the server for the current session via
GET /authn/session (deriva-py's
:meth:~deriva.core.ErmrestCatalog.get_authn_session). On a valid
session the server returns the logged-in client, and this returns that
client dict (id, display_name, email, full_name,
identities). When there is no session the endpoint returns 401/404
and this returns None.
This makes a network call. A successful (non-None) result is a safe
bet that catalog operations will work — it proves the credential is
present, unexpired, and accepted by the server's auth layer (the thing
that otherwise blanket-401s). It confirms authentication (the server
knows who you are), not authorization for any specific operation — a
write to a read-only table can still be refused with a valid session.
Returns:
| Type | Description |
|---|---|
dict | None
|
dict | None: The |
Raises:
| Type | Description |
|---|---|
HTTPError
|
For HTTP errors other than 401/404 (e.g. a 5xx server error) — these are real failures, not a "no session" answer, so they propagate. |
Example
who = ml.whoami() # doctest: +SKIP who["display_name"] if who else "not logged in" # doctest: +SKIP 'user@example.org'
Source code in src/deriva_ml/core/base.py
809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 | |
DerivaMLConfig
Bases: BaseModel
Configuration model for DerivaML instances.
This Pydantic model defines all configurable parameters for a DerivaML instance. It can be used directly or via Hydra configuration files.
Attributes:
| Name | Type | Description |
|---|---|---|
hostname |
str
|
Hostname of the Deriva server (e.g., 'deriva.example.org'). |
catalog_id |
str | int
|
Catalog identifier, either numeric ID or catalog name. |
domain_schemas |
str | set[str] | None
|
Optional set of domain schema names. If None, auto-detects all non-system schemas. Use this when working with catalogs that have multiple user-defined schemas. |
default_schema |
str | None
|
The default schema for table creation operations. If None and there is exactly one domain schema, that schema is used. If there are multiple domain schemas, this must be specified for table creation to work without explicit schema parameters. |
project_name |
str | None
|
Project name for organizing outputs. Defaults to default_schema. |
cache_dir |
str | Path | None
|
Directory for caching downloaded datasets. Defaults to working_dir/cache. |
working_dir |
str | Path | None
|
Base directory for computation data. Defaults to ~/deriva-ml. |
hydra_runtime_output_dir |
str | Path | None
|
Hydra's runtime output directory (set automatically). |
ml_schema |
str
|
Schema name for ML tables. Defaults to 'deriva-ml'. |
logging_level |
Any
|
Logging level for DerivaML. Defaults to WARNING. |
deriva_logging_level |
Any
|
Logging level for Deriva libraries. Defaults to WARNING. |
credential |
Any
|
Authentication credentials. If None, retrieved automatically. |
s3_bucket |
str | None
|
S3 bucket URL for dataset bag storage (e.g., 's3://my-bucket'). If provided, enables MINID creation and S3 upload for dataset exports. If None, MINID functionality is disabled regardless of use_minid setting. |
use_minid |
bool | None
|
Whether to use MINID service for dataset bags. Only effective when s3_bucket is configured. Defaults to True when s3_bucket is set, False otherwise. |
clean_execution_dir |
bool
|
Whether to automatically clean execution working directories after successful upload. Defaults to True. Set to False to retain local copies of execution outputs for debugging or manual inspection. |
mode |
ConnectionMode | str
|
Connection mode. |
Example
DerivaMLConfig requires a Hydra context to validate; skipping
the example at doctest time but the call shape is real:
config = DerivaMLConfig( # doctest: +SKIP ... hostname='deriva.example.org', ... catalog_id=1, ... default_schema='my_domain', ... logging_level=logging.INFO ... )
Source code in src/deriva_ml/core/config.py
71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 | |
compute_workdir
staticmethod
compute_workdir(
working_dir: str | Path | None,
catalog_id: str | int | None = None,
hostname: str | None = None,
) -> Path
Compute the effective working directory path.
Creates a standardized working directory path. If a base directory is provided, appends the current username to prevent conflicts between users. If no directory is provided, uses ~/.deriva-ml. The hostname and catalog_id are appended to separate data from different servers and catalogs.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
working_dir
|
str | Path | None
|
Base working directory path, or None for default. |
required |
catalog_id
|
str | int | None
|
Catalog identifier to include in the path. If None, no catalog subdirectory is created. |
None
|
hostname
|
str | None
|
Server hostname to include in the path. If None, no hostname subdirectory is created. |
None
|
Returns:
| Name | Type | Description |
|---|---|---|
Path |
Path
|
Absolute path to the working directory. |
Example
Path structure for a shared-dir working tree:
/
/ /deriva-ml/ / p = DerivaMLConfig.compute_workdir('/shared/data', '52', 'ml.example.org') str(p).endswith('/deriva-ml/ml.example.org/52') True str(p).startswith('/shared/data/') True
Path structure for the default (~/.deriva-ml) tree:
/.deriva-ml/ / p = DerivaMLConfig.compute_workdir(None, 1, 'localhost') str(p).endswith('/.deriva-ml/localhost/1') True
Source code in src/deriva_ml/core/config.py
195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 | |
init_working_dir
init_working_dir() -> DerivaMLConfig
Initialize working directory and resolve use_minid after model validation.
Working-directory resolution mirrors DerivaML.__init__ so the
two construction paths produce the same effective path:
- If the user explicitly passed
working_dir=..., that exact path is honored as-is (made absolute). The auto-namespace append of<user>/deriva-ml/<host>/<catalog>is not applied — silently appending to a path the user explicitly chose would be a surprise (a user passingworking_dir="/tmp/wd"would have ended up at/tmp/wd/<user>/deriva-ml/<host>/<catalog>and not been told). - If
working_diris None,compute_workdirproduces the default per-host/catalog-namespaced path under~/.deriva-ml/....
The Hydra runtime output dir is read defensively: when the
config is instantiated outside a Hydra context (notebook,
ad-hoc script, MCP server, unit test), HydraConfig.get()
raises ValueError: HydraConfig was not set. We treat that
as "no Hydra runtime output dir" rather than a fatal config
error.
Resolves the use_minid flag based on s3_bucket configuration: - If use_minid is explicitly set, use that value (but it only takes effect if s3_bucket is set) - If use_minid is None (auto), set it to True if s3_bucket is configured, False otherwise
Returns:
| Name | Type | Description |
|---|---|---|
Self |
DerivaMLConfig
|
The configuration instance with initialized paths. |
Source code in src/deriva_ml/core/config.py
135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 | |
DerivaMLException
Bases: Exception
Base exception class for all DerivaML errors.
This is the root exception for all DerivaML-specific errors. Catching this exception will catch any error raised by the DerivaML library.
Attributes:
| Name | Type | Description |
|---|---|---|
_msg |
The error message stored for later access. |
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
msg
|
str
|
Descriptive error message. Defaults to empty string. |
''
|
Example
raise DerivaMLException("Failed to connect to catalog") # doctest: +SKIP DerivaMLException: Failed to connect to catalog
Source code in src/deriva_ml/core/exceptions.py
92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 | |
DerivaMLInvalidTerm
Bases: DerivaMLNotFoundError
Exception raised when a vocabulary term is not found or invalid.
Raised when attempting to look up or use a term that doesn't exist in a controlled vocabulary table, or when a term name/synonym cannot be resolved.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
vocabulary
|
str
|
Name of the vocabulary table being searched. |
required |
term
|
str
|
The term name that was not found. |
required |
msg
|
str
|
Additional context about the error. Defaults to "Term doesn't exist". |
"Term doesn't exist"
|
Example
raise DerivaMLInvalidTerm("Diagnosis", "unknown_condition") # doctest: +SKIP DerivaMLInvalidTerm: Invalid term unknown_condition in vocabulary Diagnosis: Term doesn't exist.
Source code in src/deriva_ml/core/exceptions.py
313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 | |
DerivaMLTableTypeError
Bases: DerivaMLDataError
Exception raised when a RID or table is not of the expected type.
Raised when an operation requires a specific table type (e.g., Dataset, Execution) but receives a RID or table reference of a different type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
table_type
|
str
|
The expected table type (e.g., "Dataset", "Execution"). |
required |
table
|
str
|
The actual table name or RID that was provided. |
required |
Example
raise DerivaMLTableTypeError("Dataset", "1-ABC123") # doctest: +SKIP DerivaMLTableTypeError: Table 1-ABC123 is not of type Dataset.
Source code in src/deriva_ml/core/exceptions.py
366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 | |
ExecAssetType
Bases: StrEnum
Execution asset type identifiers.
Defines the types of assets that can be produced or consumed during an execution. These types are used to categorize files associated with workflow runs.
Attributes:
| Name | Type | Description |
|---|---|---|
input_file |
str
|
Input file consumed by the execution. |
output_file |
str
|
Output file produced by the execution. |
notebook_output |
str
|
Jupyter notebook output from the execution. |
model_file |
str
|
Machine learning model file (e.g., .pkl, .h5, .pt). |
Source code in src/deriva_ml/core/enums.py
166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 | |
ExecMetadataType
Bases: StrEnum
Execution metadata type identifiers.
Defines the types of metadata that can be associated with an execution.
Attributes:
| Name | Type | Description |
|---|---|---|
execution_config |
str
|
General execution configuration data. |
runtime_env |
str
|
Runtime environment information. |
hydra_config |
str
|
Hydra YAML configuration files (config.yaml, overrides.yaml). |
deriva_config |
str
|
DerivaML execution configuration (configuration.json). |
metrics_file |
str
|
Training-metric log file (typically JSONL, one
record per evaluation point — per epoch, per eval step, etc.).
Written during execution via |
Source code in src/deriva_ml/core/enums.py
141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 | |
FileSpec
Bases: BaseModel
Specification for a file to be added to the Deriva catalog.
Represents file metadata required for creating entries in the File table. Handles URL normalization, ensuring local file paths are converted to tag URIs that uniquely identify the file's origin.
Attributes:
| Name | Type | Description |
|---|---|---|
url |
str
|
File location as URL or local path. Local paths are converted to tag URIs. |
md5 |
str
|
MD5 checksum for integrity verification. |
length |
int
|
File size in bytes. |
description |
str | None
|
Optional description of the file's contents or purpose. |
file_types |
list[str] | None
|
List of file type classifications from the Asset_Type vocabulary. |
Note
The 'File' type is automatically added to file_types if not present when using create_filespecs().
Example
spec = FileSpec( ... url="/data/results.csv", ... md5="d41d8cd98f00b204e9800998ecf8427e", ... length=1024, ... description="Analysis results", ... file_types=["CSV", "Data"] ... )
Source code in src/deriva_ml/core/filespec.py
42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 | |
create_filespecs
classmethod
create_filespecs(
path: Path | str,
description: str,
file_types: list[str]
| Callable[[Path], list[str]]
| None = None,
) -> Generator[FileSpec, None, None]
Generate FileSpec objects for a file or directory.
Creates FileSpec objects with computed MD5 checksums for each file found. For directories, recursively processes all files. The 'File' type is automatically prepended to file_types if not already present.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
path
|
Path | str
|
Path to a file or directory. If directory, all files are processed recursively. |
required |
description
|
str
|
Description to apply to all generated FileSpecs. |
required |
file_types
|
list[str] | Callable[[Path], list[str]] | None
|
Either a static list of file types, or a callable that takes a Path and returns a list of types for that specific file. Allows dynamic type assignment based on file extension, content, etc. |
None
|
Yields:
| Name | Type | Description |
|---|---|---|
FileSpec |
FileSpec
|
A specification for each file with computed checksums and metadata. |
Example
Static file types: >>> specs = FileSpec.create_filespecs("/data/images", "Images", ["Image"]) # doctest: +SKIP
Dynamic file types based on extension: >>> def get_types(path): # doctest: +SKIP ... ext = path.suffix.lower() ... return {"png": ["PNG", "Image"], ".jpg": ["JPEG", "Image"]}.get(ext, []) >>> specs = FileSpec.create_filespecs("/data", "Mixed files", get_types) # doctest: +SKIP
Source code in src/deriva_ml/core/filespec.py
103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 | |
read_filespec
staticmethod
read_filespec(
path: Path | str,
) -> Generator[FileSpec, None, None]
Read FileSpec objects from a JSON Lines file.
Parses a JSONL file where each line is a JSON object representing a FileSpec. Empty lines are skipped. This is useful for batch processing pre-computed file specifications.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
path
|
Path | str
|
Path to the .jsonl file containing FileSpec data. |
required |
Yields:
| Name | Type | Description |
|---|---|---|
FileSpec |
FileSpec
|
Parsed FileSpec object for each valid line. |
Example
for spec in FileSpec.read_filespec("files.jsonl"): # doctest: +SKIP ... print(f"{spec.url}: {spec.md5}")
Source code in src/deriva_ml/core/filespec.py
164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 | |
validate_file_url
classmethod
validate_file_url(url: str) -> str
Examine the provided URL. If it's a local path, convert it into a tag URL.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
url
|
str
|
The URL to validate and potentially convert |
required |
Returns:
| Type | Description |
|---|---|
str
|
The validated/converted URL |
Raises:
| Type | Description |
|---|---|
ValidationError
|
If the URL is not a file URL |
Source code in src/deriva_ml/core/filespec.py
78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 | |
FileUploadState
Bases: BaseModel
Tracks the state and result of a file upload operation.
Attributes:
| Name | Type | Description |
|---|---|---|
state |
UploadState
|
Current state of the upload (success, failed, etc.). |
status |
str
|
Detailed status message. |
result |
Any
|
Upload result data, if any. |
Source code in src/deriva_ml/core/ermrest.py
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 | |
MLAsset
Bases: StrEnum
Asset type identifiers.
Defines the types of assets that can be associated with executions.
Attributes:
| Name | Type | Description |
|---|---|---|
execution_metadata |
str
|
Metadata about an execution. |
execution_asset |
str
|
Asset produced by an execution. |
Source code in src/deriva_ml/core/enums.py
98 99 100 101 102 103 104 105 106 107 108 109 | |
MLVocab
Bases: StrEnum
Controlled vocabulary table identifiers.
Defines the names of controlled vocabulary tables used in DerivaML. These tables store standardized terms with descriptions and synonyms for consistent data classification across the catalog.
Attributes:
| Name | Type | Description |
|---|---|---|
dataset_type |
str
|
Dataset classification vocabulary (e.g., "Training", "Test"). |
workflow_type |
str
|
Workflow classification vocabulary (e.g., "Python", "Notebook"). |
asset_type |
str
|
Asset/file type classification vocabulary (e.g., "Image", "CSV"). |
asset_role |
str
|
Asset role vocabulary for execution relationships (e.g., "Input", "Output"). |
execution_status |
str
|
Execution status vocabulary for execution lifecycle states. |
feature_name |
str
|
Feature name vocabulary for ML feature definitions. |
Source code in src/deriva_ml/core/enums.py
74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | |
UploadState
Bases: Enum
File upload operation states.
Represents the various states a file upload operation can be in, from initiation to completion.
Attributes:
| Name | Type | Description |
|---|---|---|
success |
int
|
Upload completed successfully. |
failed |
int
|
Upload failed. |
pending |
int
|
Upload is queued. |
running |
int
|
Upload is in progress. |
paused |
int
|
Upload is temporarily paused. |
aborted |
int
|
Upload was aborted. |
cancelled |
int
|
Upload was cancelled. |
timeout |
int
|
Upload timed out. |
Source code in src/deriva_ml/core/enums.py
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
configure_logging
configure_logging(
level: int = logging.WARNING,
deriva_level: int | None = None,
format_string: str = DEFAULT_FORMAT,
handler: Handler | None = None,
) -> logging.Logger
Configure logging for DerivaML and related libraries.
This function sets up logging levels for DerivaML, related libraries (deriva-py, bdbag, bagit), and Hydra loggers. It is designed to:
- Configure only specific logger namespaces, not the root logger
- Respect Hydra's logging configuration when running under Hydra
- Allow deriva-py libraries to have a separate logging level
The logging level hierarchy
- deriva_ml logger: uses
level - Hydra loggers: follow
level(deriva_ml level) - Deriva/bdbag/bagit loggers: use
deriva_level(defaults tolevel)
When running under Hydra
- Only sets log levels on specific loggers
- Does NOT add handlers (Hydra has already configured them)
- Does NOT call basicConfig()
When running standalone (no Hydra): - Sets log levels on specific loggers - Adds a StreamHandler to deriva_ml logger if none exists - Still does NOT touch the root logger or call basicConfig()
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
level
|
int
|
Log level for deriva_ml and Hydra loggers. Defaults to WARNING. |
WARNING
|
deriva_level
|
int | None
|
Log level for deriva-py libraries (deriva, bagit, bdbag).
If None, uses the same level as |
None
|
format_string
|
str
|
Format string for log messages (used only when adding handlers outside Hydra context). |
DEFAULT_FORMAT
|
handler
|
Handler | None
|
Optional handler to add to the deriva_ml logger. If None and not running under Hydra, uses StreamHandler with format_string. |
None
|
Returns:
| Type | Description |
|---|---|
Logger
|
The configured deriva_ml logger. |
Example
import logging
Same level for everything
_ = configure_logging(level=logging.DEBUG)
Verbose DerivaML, quieter deriva-py libraries
_ = configure_logging( ... level=logging.INFO, ... deriva_level=logging.WARNING, ... )
Source code in src/deriva_ml/core/logging_config.py
122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 | |
get_logger
get_logger(
name: str | None = None,
) -> logging.Logger
Get a DerivaML logger.
Three name forms are accepted:
None— returns the mainderiva_mllogger.- A short suffix (no dots), e.g.
get_logger("dataset")— returnsderiva_ml.dataset. - A full module
__name__(with or without thederiva_ml.prefix), e.g.get_logger(__name__)from insidederiva_ml/dataset/dataset.py— returnsderiva_ml.dataset.dataset. Names that already start withderiva_mlare used as-is; the bare string"deriva_ml"is treated identically toNone.
Form (3) is the canonical project-wide pattern: every module
writes logger = get_logger(__name__) so log messages
carry their source module in the hierarchy.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name
|
str | None
|
Sub-logger name. See above for accepted forms. |
None
|
Returns:
| Type | Description |
|---|---|
Logger
|
The configured logger instance. |
Example
logger = get_logger() # deriva_ml get_logger("dataset").name # deriva_ml.dataset 'deriva_ml.dataset' get_logger("deriva_ml.dataset").name # already-prefixed 'deriva_ml.dataset' get_logger("deriva_ml").name # bare root 'deriva_ml'
Source code in src/deriva_ml/core/logging_config.py
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 | |
is_hydra_initialized
is_hydra_initialized() -> bool
Check if running within an initialized Hydra context.
This is used to determine whether Hydra is managing logging configuration. When Hydra is initialized, we avoid adding handlers or calling basicConfig since Hydra has already configured logging via dictConfig.
Returns:
| Type | Description |
|---|---|
bool
|
True if Hydra's GlobalHydra is initialized, False otherwise. |
Example
if is_hydra_initialized(): ... # Hydra is managing logging ... pass
Source code in src/deriva_ml/core/logging_config.py
57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | |